Writing Events Is All You Need
Writing Events Is All You Need
Storing state-only data breaks agentic workflows. You cannot trust an agent’s answers when the underlying data has already discarded the context those answers depend on. Yet engineers keep treating this as a read-side problem, stitching intent from disparate sources instead of capturing it at write time.
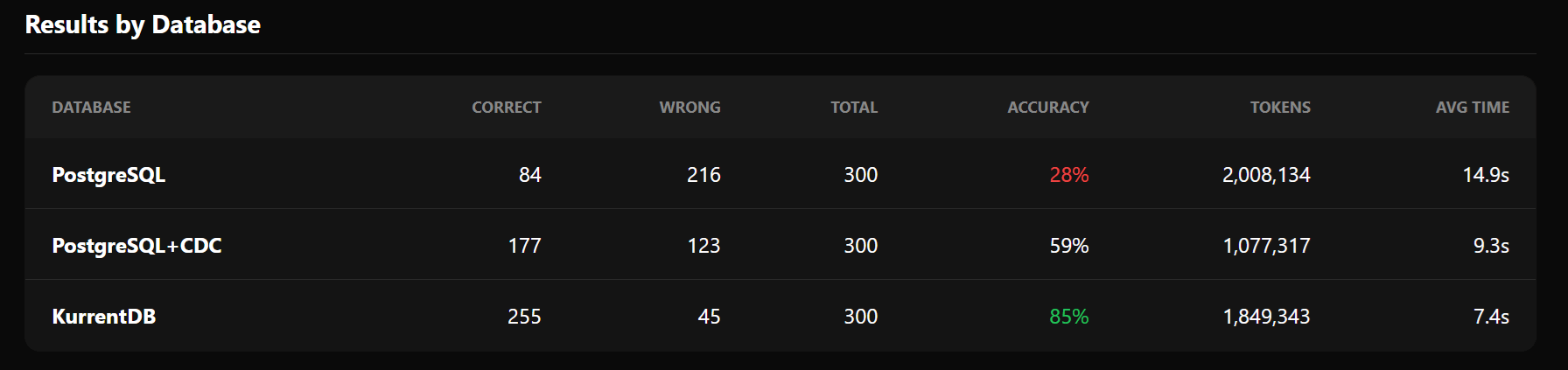
We ran 300 benchmark questions across three storage models. Storing only the current state scored 28%. Storing current state with change data capture scored 59%. Finally, storing full event streams, scored 85%. The difference is not the AI model. It is what you chose to store. Your atomic unit of storage should be an event. Without it, your agentic data lacks the full resolution needed to ensure accuracy and trust.
You can browse the complete benchmark at: https://kurrent-io.github.io/agentic_benchmarks/
State Overwrites Destroy Intent
An event is an immutable record of something meaningful that has already happened in a system. Events are named in the past tense (OrderPlaced, OrderCancelledByCustomer) and carry the full context of what changed, who changed it, and why. Unlike a database row, an event is never overwritten; current state is derived by replaying the sequence. History becomes a first-class citizen of the system.
For example, we trace a single customer order through three storage models: one capturing only current state, one adding field-level change history, and one recording the full event stream. The question is simple: what can each approach tell an agent about what happened and why?
Take a simple example. A customer places an order, then cancels it. In a state-only system, the record shows status = cancelled. The agent can see what IS, but not what WAS, or WHY. This is not a bug. It is by design. Relational databases are built to store current state. Every update overwrites the previous value, and the database faithfully reflects what IS — but it cannot tell you what WAS or WHY.
For a human querying a dashboard, current state is often sufficient. But for an AI agent tasked with understanding, diagnosing, or auditing a system, current state is woefully incomplete.
Designing the Benchmark
We tested three data storage models, each built on a different philosophy of what to store:
- PostgreSQL with Only Current State stores the current state of each entity. Every update overwrites the previous value. The atomic unit is the row — a snapshot of the entity right now.
- PostgreSQL with Change Data Capture (CDC) captures before-and-after values for each change. When a field changes from A to B, both values are recorded. The atomic unit is the field change — a diff between two states.
- KurrentDB (Event Sourcing) stores an immutable stream of events, each representing something that happened in the domain. The atomic unit is the event — a named action with full context, including the reason it occurred.
Methodology
We used the following publicly available data:
- Berka (Banking) - https://data.world/lpetrocelli/czech-financial-dataset-real-anonymized-transactions
- BTS Airline On-Time Performance data - https://www.transtats.bts.gov/DL_SelectFields.aspx?gnoession_VQ=FGJ
- GitHub Archive - https://www.gharchive.org/
- MovieLens - https://grouplens.org/datasets/movielens/
- Olist E-Commerce - https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce
The data sets were then interrogated by an agent through either PostgreSQL’s official MCP Server or KurrentDB’s official MCP Server, with a series of questions, each of a specific type as described below. The response is then judged by another agent based on the expected answer that we have pre-computed in advance. The possible results are either FAIL or PASS.
In order to derive compatible datasets and questions, the benchmark converts data in both directions — CRUD-shaped → Events and Events → CRUD-shaped — to avoid testing data that was simply designed for one model. Naturally CRUD datasets like the Olist e-commerce orders and Berka banking balances were synthetically enriched into event streams. Naturally event-based data like GitHub pull requests was deliberately flattened into CRUD tables. The result is the same regardless of direction: when you flatten events into CRUD, information is destroyed; when you enrich CRUD into events, information is added.
Questions are organized into a five-tier framework across five real-world domains (e-commerce, banking, software development, aviation, and movie ratings):
Question Five-Tier Framework
- Tier 1 — Easy: Current State. “What is the current status of order X?” All three databases can answer this.
- Tier 2 — Medium: Change History. “What was the previous status before it changed?” CDC and KurrentDB can answer; plain CRUD cannot.
- Tier 3 — Hard: Intent and Reason. “Why was the order cancelled?” Only the event store can answer this, because the event itself carries the reason (e.g., Order cancelled by customer).
- Tier 4 — Temporal: Cross-Event Ordering. “How many review rounds did this PR go through?” These require reasoning across a sequence of events in chronological order. PostgreSQL and CDC both fail here; only KurrentDB preserves the complete sequence.
- Tier 5 — Adversarial: False Premise Detection. “Why was the order cancelled by the system?” (when in fact the customer cancelled it). The correct answer requires detecting and correcting the false assumption. Only the event stream carries the named event OrderCancelledByCustomer, which directly refutes the false premise.
Questions are generated dynamically from templates with pools of possible values, so expected answers are derived directly from the sampled values. This ensures correctness by construction and allows scaling the benchmark arbitrarily. Full benchmark details, templates, and runner are available at the project repository: https://github.com/kurrent-io/agentic_benchmarks
Results
Across 300 questions, the pattern is clear:
| Database | Tier 1 (Easy) | Tier 2 (Medium) | Tier 3 (Hard) | Overall |
|---|---|---|---|---|
| PostgreSQL | ~70% | ~0% | ~0% | 28% |
| PostgreSQL+CDC | ~80% | ~70% | ~0% | 59% |
| KurrentDB | ~100% | ~100% | ~100% | 85% |
As you can see from the results, when using only current-state, agents can only answer current state questions reasonably but fail completely on historical and intent queries. CDC improves on history but still cannot explain why changes occurred. KurrentDB, storing full event streams with action semantics, answers every category of question.
OK, What If I Just Used PostgreSQL?
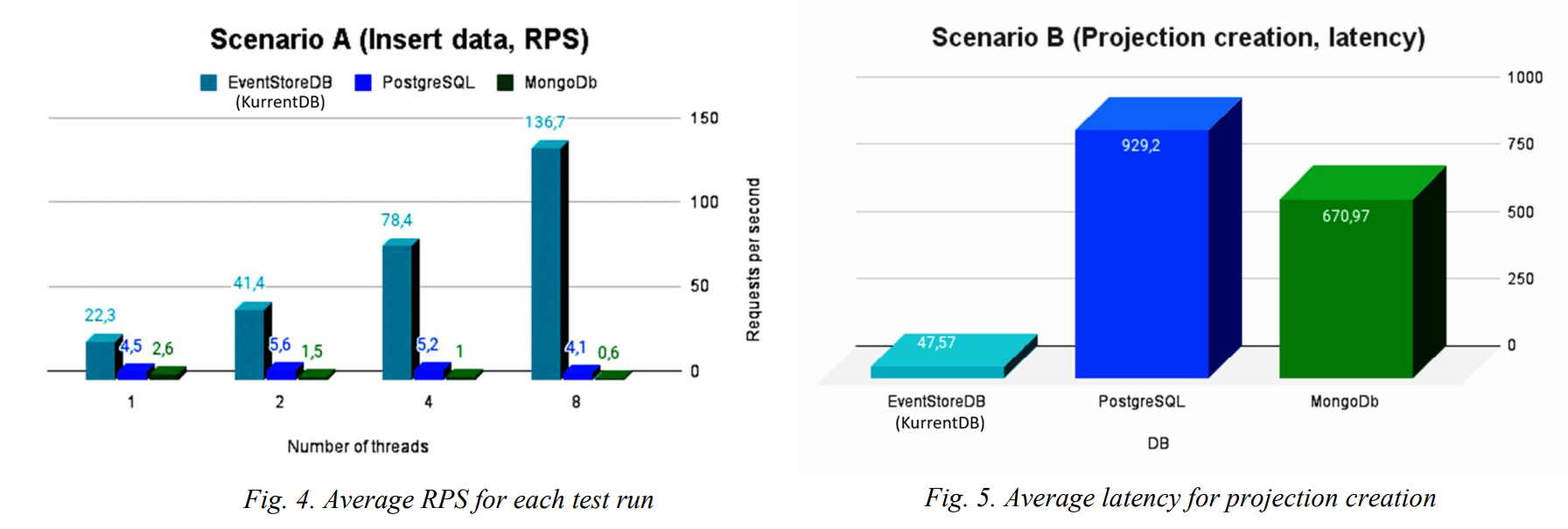
You can, but event sourcing is append-heavy, and purpose-built event stores outperform PostgreSQL under concurrent writes. As Malyi and Serdyuk showed in their 2024 benchmark, KurrentDB’s write throughput improves under concurrency. Without native stream semantics, projections, or stream-level concurrency control, you end up rebuilding an event store in application code.
Conclusion
The results are unambiguous. Current-state storage answers only the easiest questions. CDC adds history but still cannot explain causation. Only event-sourced data gave the agent everything it needed to answer every tier.
The bottleneck was never the agent; it was the data. Intent not captured at write time cannot be recovered at read time, no matter how sophisticated the retrieval.
The benchmark framework, templates, and runner are available at the project repository: https://github.com/kurrent-io/agentic\_benchmarks
