We'll End Up Where We Started. Except with Different Technology.
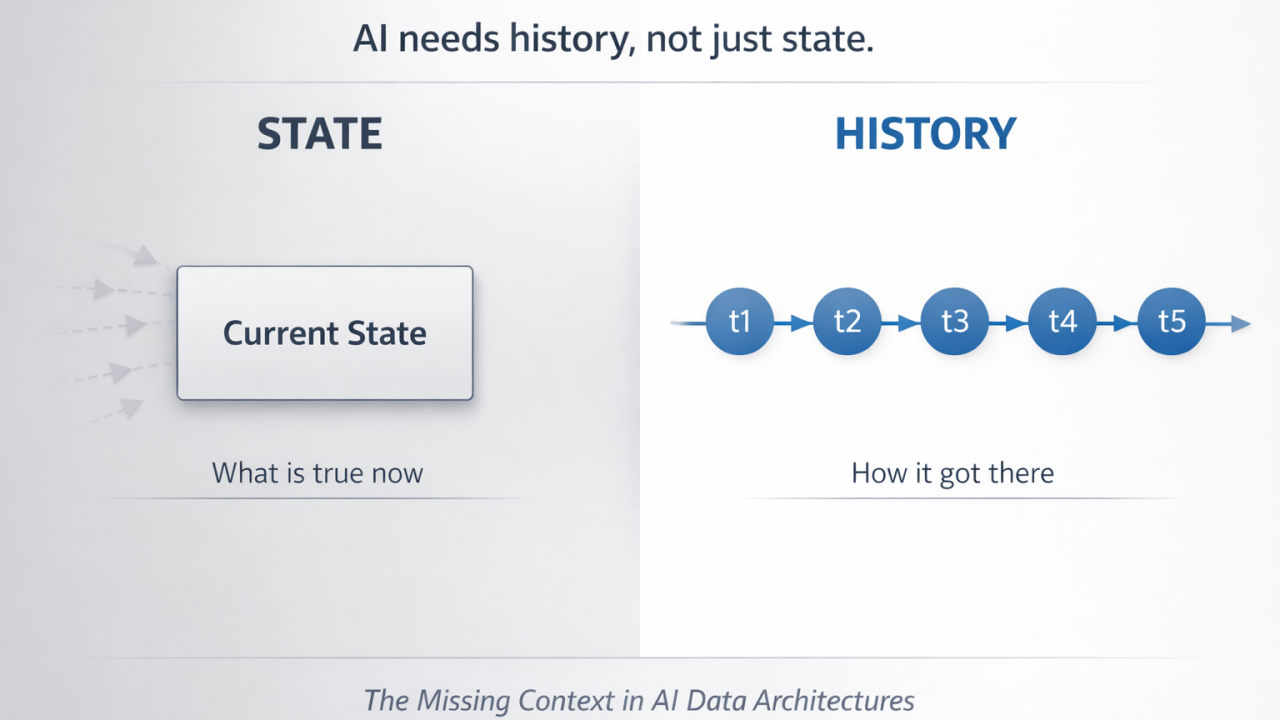
AI needs history
Lately, as I’ve been reading through how teams are designing AI data infrastructure, two patterns keep showing up. One approach is to add smarter, dedicated layers to the stack — semantic caching, memory stores, CDC pipelines. The other is to simplify and consolidate — push more of that responsibility into the backend database you already have. Both approaches make sense. Both are solving real pain. But the more I looked at them, the more it felt like something was missing. Not because the tools aren’t good — they are. But because neither approach really addresses the underlying problem.
A quick note before you dive in.
This piece ended up being longer than I expected. The problem itself turned out to be older than it looks. If you’re short on time, the diagrams carry most of the argument. The rest of the write-up is really about explaining why those diagrams look the way they do — and what that means when you’re making architectural decisions. Either way, I’d recommend at least skimming the questions at the end before committing to a direction.
Key Takeaways
Redis is a database, not just a cache — but every database has a lane.
Redis is excellent for in-memory operational data, flexible data structures, and low-latency lookups. But the moment an AI system needs persistent event history, unbounded audit logs, or long-lived context, you’ve moved outside that lane. At that point, the swim lane matters more than the tool.
The industry has two responses to AI data pain — and neither fixes the root cause.
One response adds smarter layers. The other collapses everything into the backend database you already have. Both improve something. Neither changes the underlying primitive: state, not history.
CDC gives you a state. State is not history.
CDC can tell you what is true now. It cannot tell you the full sequence of events that produced that truth, the intermediate states along the way, or what that means when someone asks later, “What exactly happened here?” It gives you nouns, not verbs.
A checkpoint tells you where the agent stopped. An event log tells you what it actually did.
Agent checkpointing records position, not history. Recovery from a checkpoint often means re-inference. Recovery from an event stream is deterministic, auditable, and doesn’t require paying for the same reasoning twice.
The primitive is the problem, not the number of systems.
Whether you have four systems or one, if the primitive is state, the gap is still there: no native audit trail, no causal ordering, no regulator-ready answer. Fewer systems don’t automatically mean a better architecture.
Event-native is not a replacement — it’s the missing layer.
KurrentDB doesn’t replace your LLM, vector database, relational database, or cache. It provides the ordered, immutable event history that makes all of them more trustworthy. Everything else can compose on top of it.
The questions from 2015 haven’t changed. The stakes have.
What happens when the dataset outgrows memory? How do you recover from failures? Who owns the write path? These were valid Redis questions a decade ago. They are valid AI architecture questions today. Same questions — much bigger consequences.
The event store is the only truly vendor-agnostic part of the stack.
Cache-first and consolidation-first designs both create deep dependencies. An event stream is different. It’s just a sequence of facts. Your model changes, your vector store changes, your cache provider changes — but the history of what actually happened in your system is still yours.
How This Started
Over the last year, two things have been circling the architecture conversation — coming from completely different directions.
The first was a vendor blog describing a modern AI stack: semantic caching, CDC pipelines, agentic memory stores — all layered on top of an LLM platform. Clean. Well thought out. Everything neatly assembled.
The second wasn’t a blog at all. It was a set of conversations I kept having with architects and engineering teams.
The question was always the same:
“We already have a backend relational database running our application — why not just use that for AI as well?” Store vectors alongside relational data. Use the same system for agent state. Add checkpointing there. Honestly, it’s a very reasonable instinct. Most teams I talk to are planning to build it exactly this way.
Both of these approaches are solving real problems. They’re not wrong. They come from engineers making practical tradeoffs under real constraints. But the more I looked at them side by side, the more they reminded me of something I had seen before — just in a different context.
A decade ago, when I was working with Redis, I remember a very similar set of conversations. And I want to be precise here — Redis was never just a cache. It’s a database, and a very powerful one at that. In-memory architecture, flexible data structures, extremely low latency — it opened up use cases that were difficult to solve any other way.
But the same questions kept coming up, over and over:
What happens when the data needs to outlive memory?
How do you keep it consistent with your system of record?
What does recovery actually look like?
Where does the write path live?
These weren’t objections. They were the right questions. We had answers — but they always came with the same caveat: Redis is exceptional in its lane. The moment you push it outside that lane, the tradeoffs start to show up.
What I’m seeing now feels very similar — just applied to AI systems.
The industry is responding in two ways:
Add more specialized layers. Or consolidate everything into the database you already have. Both approaches move things forward. But neither really addresses the underlying issue. And if I’m being honest, it feels like we’re heading toward the same place again —
just with different technology, and much larger consequences.
Redis is a Database. Let’s Be REAL.
Redis is not just a cache. It’s a database — and a really good one. It has a rich set of data structures: hashes, sorted sets, streams, geospatial indexes, probabilistic structures. I spent a few years explaining this to customers, and the ones who understood that got a lot more value out of Redis than the ones who treated it as a fast key-value store in front of Postgres. Where Redis really shines is in its native environment:
- in-memory operational data.
- Live session state.
- Real-time counters.
- Leaderboards.
- Rate limiting.
- Pub/sub messaging.
- Short-lived context.
- Low-latency lookups.
In that space, it’s hard to beat. The combination of speed and flexibility is genuinely unique. That’s its lane. The interesting part is what happens at the edge of that lane. The moment your data needs to live longer than memory can comfortably support — or your durability requirements start increasing — you begin to run into the same tradeoffs you would with any database. And for AI systems, that boundary shows up pretty quickly.
Now you’re dealing with:
- persistent event history
- causally ordered records across sessions
- append-only logs that grow over time
At that point, you’re no longer operating in Redis’s natural environment. Not because Redis isn’t good. But because the use case isn’t aligned with what it was designed for. A simple way to think about it:
Redis is like an elite sprinter. In the right race, it dominates. But if you ask it to run a marathon, you’re not testing the athlete — you’re picking the wrong event. And this isn’t really about Redis. The same pattern shows up across other in-memory operational databases — Momento, ElastiCache, Memorystore, Cosmos DB. Every system has a swim lane. What I’m seeing in a lot of AI architectures is that we’re designing systems that depend on capabilities outside those lanes.
The tools aren’t failing. The assumptions are.
So the question isn’t: Is Redis a good database? It is. The real question is: Does your AI use case actually fit within the in-memory, operational lane where Redis excels? Or have you gradually started asking it to become something it was never meant to be?
The Customer Questions from 2015 Are the Architecture Questions of 2026
When I was at Redis, the questions customers asked weren’t sales objections. They were real architectural questions. And what struck me recently is how directly those same questions map to what we’re seeing in AI systems today.
“What happens when your dataset grows beyond memory?”
Back then, this was about Redis. Today, it shows up in AI pipelines almost immediately. Event history, agent logs, audit trails — none of this is bounded. Over time, you start hitting the same constraints:
TTLs, Eviction policies, Truncation.
Not because the system is failing — but because the architecture assumes the data can be constrained.
“How do you keep Redis consistent with your system of record?”
Today, this shows up as CDC feeding AI systems. We sync data from the operational database into a vector store, a cache, or a memory layer. But CDC gives you the latest state.
It doesn’t give you:
- the sequence of events
- the intermediate decisions
- the causal chain
So yes — the systems may be consistent in terms of state. But that’s not the same as being consistent in terms of truth.
“How do you recover in case of failures?”
This one becomes very real in agent workflows.An agent fails halfway through execution. You have a checkpoint. You have a last-known state. But you don’t have a complete record of:
- what the agent did
- what data it retrieved
- what decisions it made
So recovery isn’t replay. It’s re-running the logic — often re-invoking the model — and hoping you land in the same place. That begs the question: is it deterministic?
“How do you define the write path?”
This question has gotten more complicated, not less.
Who actually owns the data now?
- the operational database?
- the CDC pipeline?
- the vector store?
- the cache?
In many AI architectures, there isn’t a clean answer. Data flows through multiple systems, and each one becomes partially authoritative in its own way.
“What happens when two systems disagree?”
This is where things get uncomfortable. Your vector store says one thing. Your cache says another. Your operational database says something else. And your AI agent reasons over whichever one it happens to query first. At that point, correctness becomes probabilistic. So is that acceptable?
None of these are new problems.
They’re the same distributed systems problems we’ve always had. They’re just showing up again — in a different stack, with much higher stakes. State-first architectures optimize for speed and simplicity. But they tend to push correctness questions down the road.
And with AI systems, those questions have a way of coming back much faster.
The Industry’s Two Responses. Neither Is Quite (At least to me).
Both of the patterns that triggered this piece are solving real problems. The industry has clearly recognized the pain — and it’s responding. But the question I kept coming back to was simple:
Are we fixing the symptom… or the actual issue?
Response A — Add More Layers
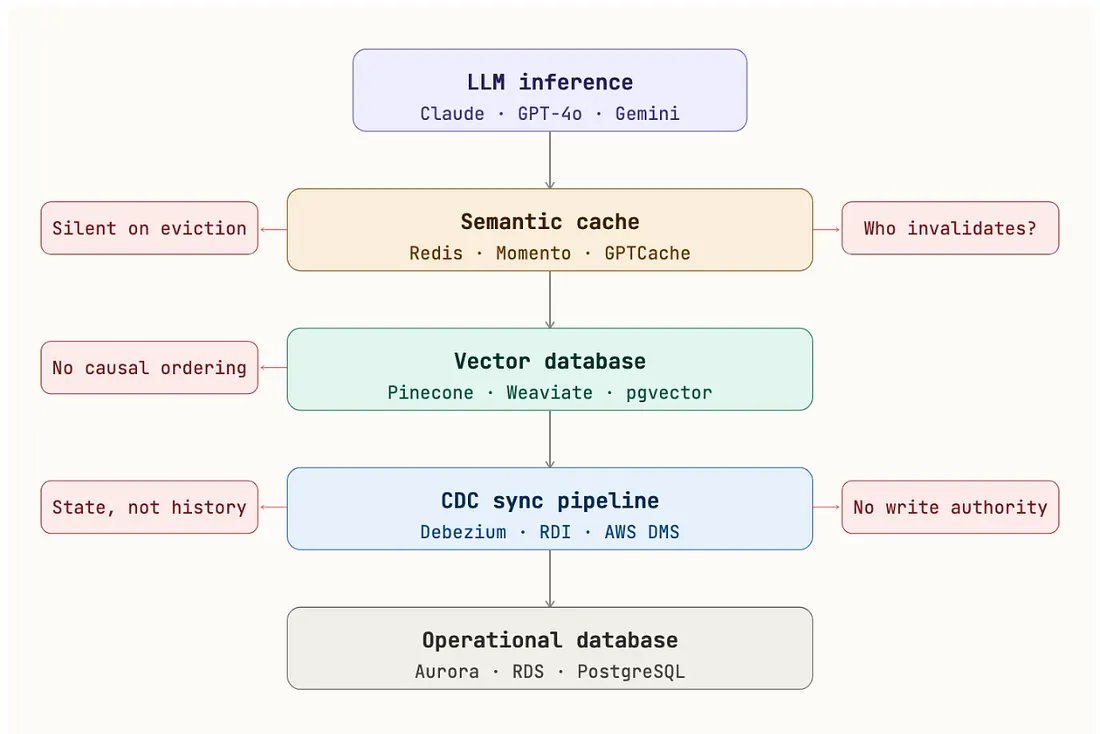
Add More Layers
One approach is to keep the existing architecture, but make each layer smarter. Add semantic caching to reduce LLM cost. Use CDC pipelines to keep data fresh. Introduce memory stores to handle agent context across sessions.
It works. Latency improves. Costs come down. Systems become more capable.
But now you’re managing multiple systems — each with its own:
- way of staying in sync
- failure behavior
- operational overhead
You’ve improved capability, but you’ve also made the system harder to reason about end-to-end.
Examples:
Redis LangCache, Bedrock AgentCore, Debezium, Mem0, LangMem, Azure AI Agent Service
What this approach really optimizes for is cost and latency. Those are important.
But the questions that kept bothering me were:
- Do I actually trust the data across these systems?
- Can I explain what happens if something goes wrong?
- Does the AI system have enough context to make the right decision?
- Or are we just moving data faster between layers that don’t fully understand it?
Response B — Collapse Everything Into One System
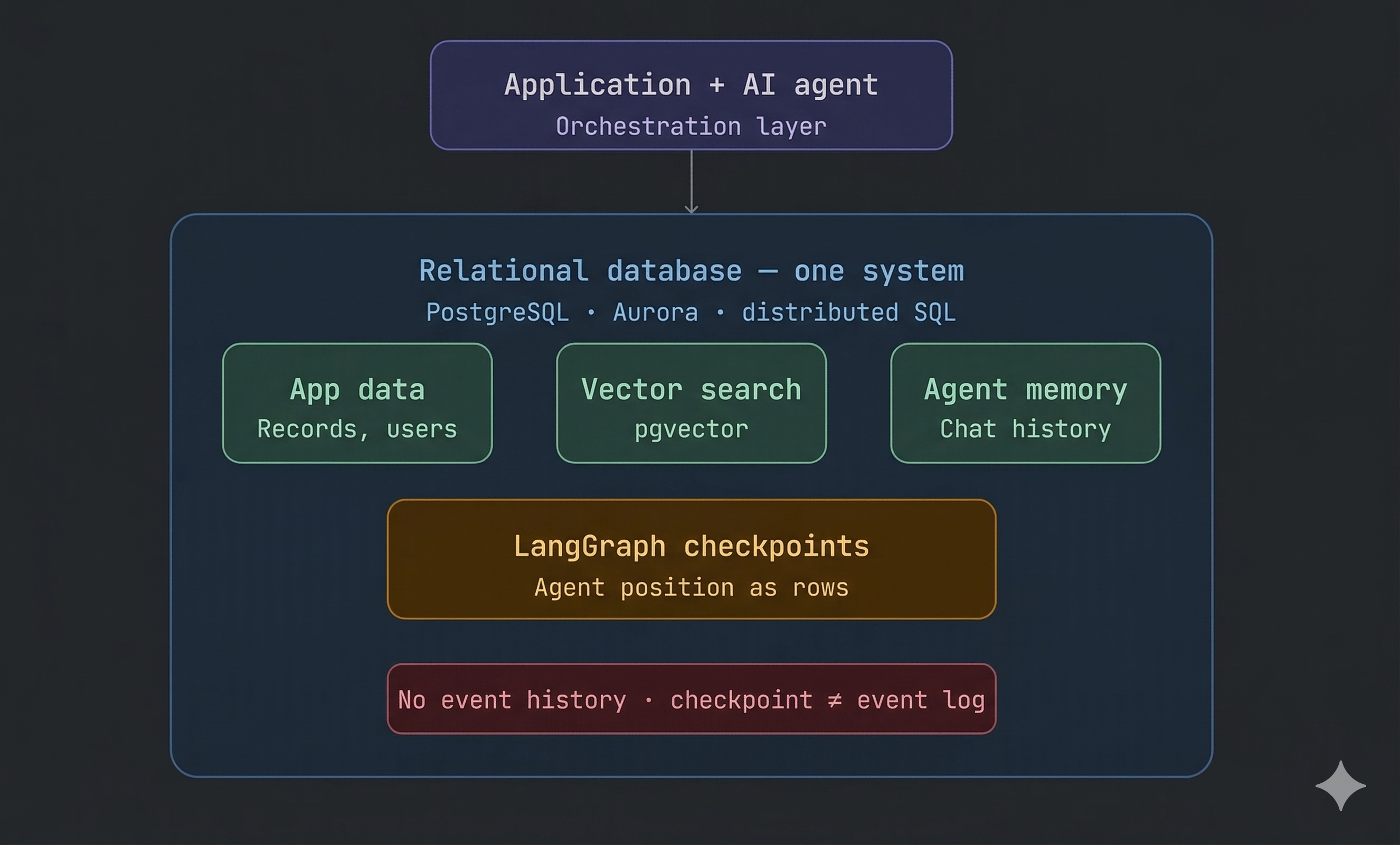
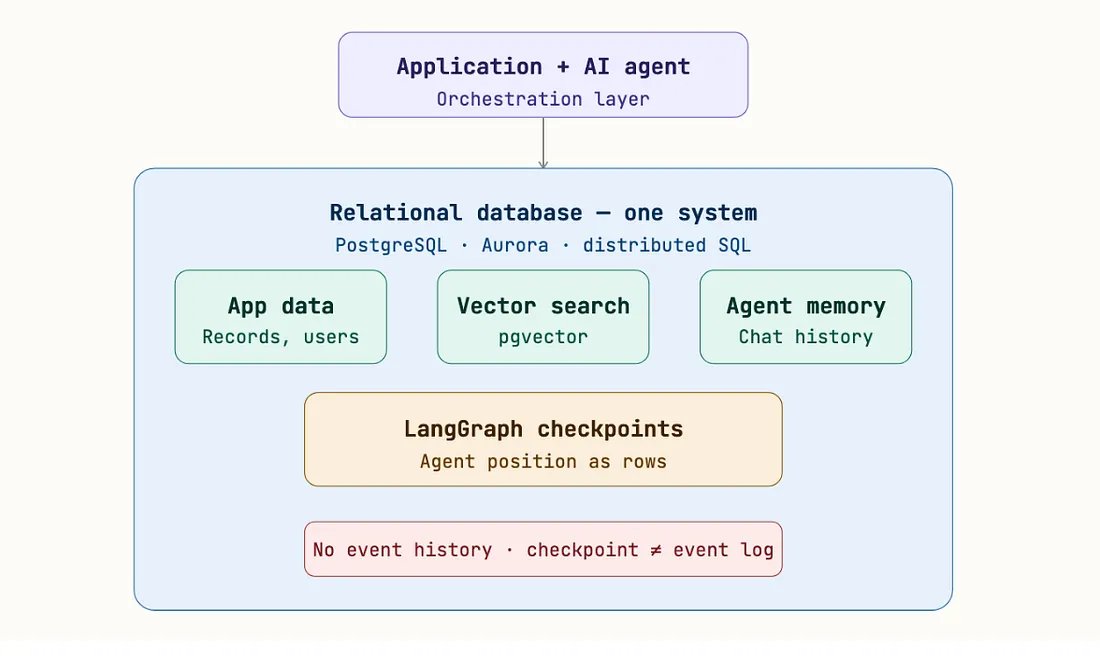
Collapse Everything Into One System
The second approach goes in the opposite direction. Most applications already have a backend database. So the instinct is: “Why not just use that for everything?”
Store vectors there. Store agent checkpoints there. Use it as the memory layer. This reduces complexity significantly.
Fewer systems. Fewer moving parts. Cleaner to operate.
Examples:
PostgreSQL + pgvector, Aurora, distributed SQL databases, LangGraph checkpointing on SQL
And to be fair — this solves a real problem: operational complexity. But it raises a different question:
Are we simplifying the system…or just putting everything into one place and hoping it holds up? Because even in this model:
- you still have the latest state
- but not the full sequence of what happened
- you still don’t have a clean way to trace decisions end-to-end
- and explaining “how we got here” is still harder than it should be
Where Both Approaches Converge
This is the part that stood out to me. Response A adds capability. Response B reduces complexity. Both move things forward. But neither really changes the core model.
You still end up with a system that knows: what is true right now
but not: how it got there. And that gap shows up later — usually when you need it the most.
Using Your Backend Database as the AI Layer Feels Right — But Does It Solve the Problem?
The instinct to consolidate everything into your existing database deserves a fair look.
This isn’t lazy architecture. Modern databases have made this easier than ever:
- pgvector brings vector search into Postgres
- many systems now support agent checkpointing
- you get IAM, backups, connection pooling — all out of the box
On the surface, it’s clean. You reduce the number of systems. You simplify operations. You move faster. Honestly, it’s hard to argue with that instinct.
But the limitation here isn’t in the engineering. It’s in what the system is actually capturing. No matter which relational database you use — or how well you run it — the question is:
what does it actually know?
So what does checkpointing really give you?
A checkpoint tells you where the agent is. An event store tells you what the agent did to get there. A checkpoint answers: “Where did it stop?” But the questions you usually need later are different:
- What did it do?
- What data did it use?
- In what order did things happen?
In most state-based systems, those answers aren’t fully there. Consolidating everything into one system reduces the number of places where data lives. But it doesn’t change what that data represents. You still have the latest state. You still don’t have the full sequence of events.
Where this leads
This is the part that stood out to me. You have two very different approaches:
- one adds layers
- the other consolidates everything
But both end up with the same gap:
- no clear history of what happened
- limited context behind decisions
- no natural ordering of events
- recovery based on re-running logic, not replaying it
When two very different approaches land in the same place, that usually tells you something. It’s not a missing feature. It’s something more fundamental.
Every Tool Has a Lane — AI Pipelines Keep Crossing Them
I’ve always thought about systems in terms of lanes. Every database is designed to do certain things really well. Relational databases are great at structured data and current state. In-memory systems are great at fast lookups and short-lived context. Each one has a place where it performs at its best. The problem starts when we push systems outside that lane.
You can make them work. You can stitch together solutions, add layers, extend them beyond what they were originally designed for. But once you cross that boundary, you start running into tradeoffs.
Not because the system is bad — but because it wasn’t optimized for that job.
What I’m seeing in a lot of AI architectures is exactly that. We’re building systems that depend on capabilities outside the natural lane of the tools we’re using. And over time, those tradeoffs start to show up.
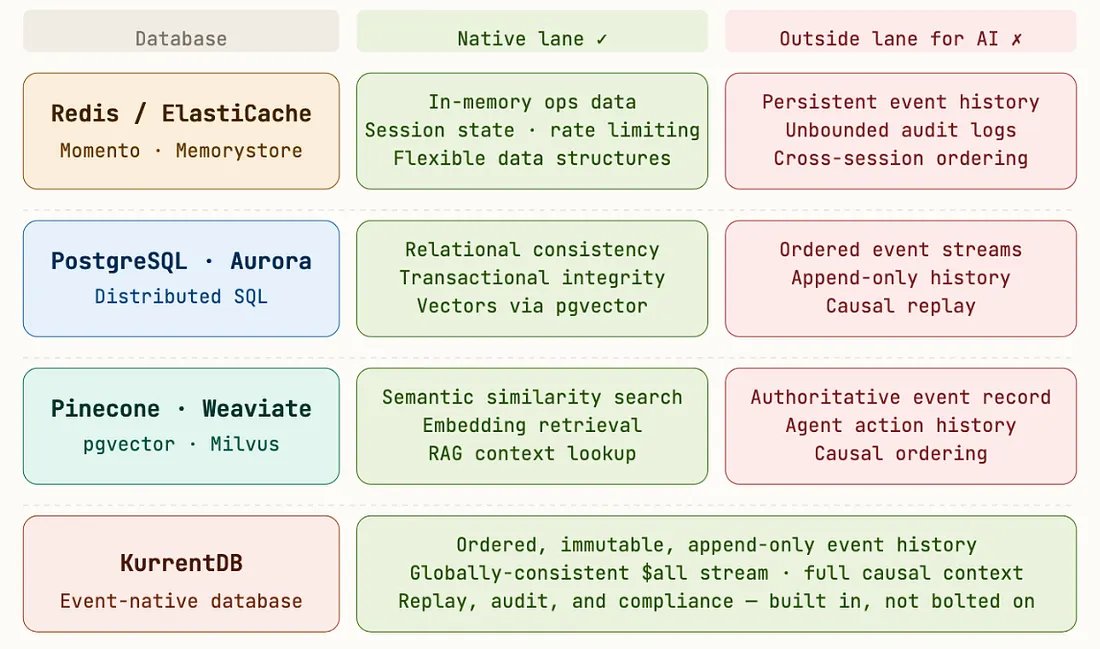
Databases and AI Capabilities
Three Failure Scenarios — You’ll See These in Any State-First Architecture
Whether you add more layers or collapse everything into one system, these failure modes show up. Not because something was implemented incorrectly. But because of how the system is designed.
Failure Scenario 1 — The System Doesn’t Know When It’s Wrong
This one is subtle — and dangerous. You have a semantic cache or stored context. The underlying data changes. But the system serving the answer doesn’t know that.
A user asks: “What’s the current savings rate?”
The system responds with a value from before a rate change. It answers confidently.
No warning. No signal that the data is stale. No easy way to trace where that answer came from. That’s not a bug. That’s the system doing exactly what it was designed to do.
Failure Scenario 2 — CDC Gives You State. State Is Not History.
CDC is everywhere in these architectures. And it’s useful. It keeps systems in sync. But what it gives you is the latest state. What it doesn’t give you:
- the sequence of events
- the intermediate steps
- the cause behind the change
You end up with: what is true now, but not: how it became true
Failure Scenario 3 — Checkpoints Aren’t Enough
This becomes very real with agent workflows. An agent runs a multi-step process. Let’s say it gets to step 4 out of 7 — and fails. The checkpoint tells you where it stopped.
But it doesn’t tell you:
- what it did in steps 1–3
- what data it used
- what decisions it made
- whether it already triggered downstream actions
So recovery usually means:
re-running the process, re-invoking the model and hoping you land in the same place - deterministic. But that’s not guaranteed.
Different Architectures. Same Gap.
This is the part that stood out to me.
Across everything I’ve looked at — semantic caching, CDC pipelines, memory stores, database consolidation — the same pattern shows up.
You still end up with:
- gaps in data freshness
- no clear ordering across systems
- incomplete context for decisions
- recovery based on re-running, not replaying
Different designs. Same gap.
Where the Difference Shows Up
If you step back and compare how these systems behave, a few patterns become clear.
Data freshness
State-first systems depend on when data was last written or synced.
Caches expire. CDC lags. So staleness is possible — and often silent.
With an event-based approach, state is derived from a continuous stream of changes. You’re not relying on when something was last updated. You’re rebuilding it from what actually happened.
Ordering
In most systems today, ordering is local.
- per table
- per service
- per session
There’s no single timeline across everything. Which makes it hard to answer: “What happened first?” An event stream gives you that timeline.
Recovery
State-first systems recover from a position. Event-based systems recover from a sequence. That difference matters. One re-runs logic. The other replays what already happened.
Understanding what happened
In most systems, answering: “What exactly happened here?” requires stitching together:
- logs
- tables
- multiple systems
With an event history, that answer already exists.
Complexity
Adding layers increases flexibility — but also coordination. Collapsing into one system reduces operational overhead — that part is real. But neither approach removes the underlying gap.
Ownership of data
In layered systems, data is spread across:
- caches
- databases
- pipelines
In consolidated systems, everything sits in one place — but still as a state. In both cases, understanding the full story requires reconstruction.
One Honest Observation
Consolidating everything into your backend database does simplify operations.
That’s a real advantage.
Fewer systems. Less coordination. Easier to run. But that’s not the dimension that usually causes problems later. The harder question is:
Can the system explain what it did? And that’s where this gap tends to show up.
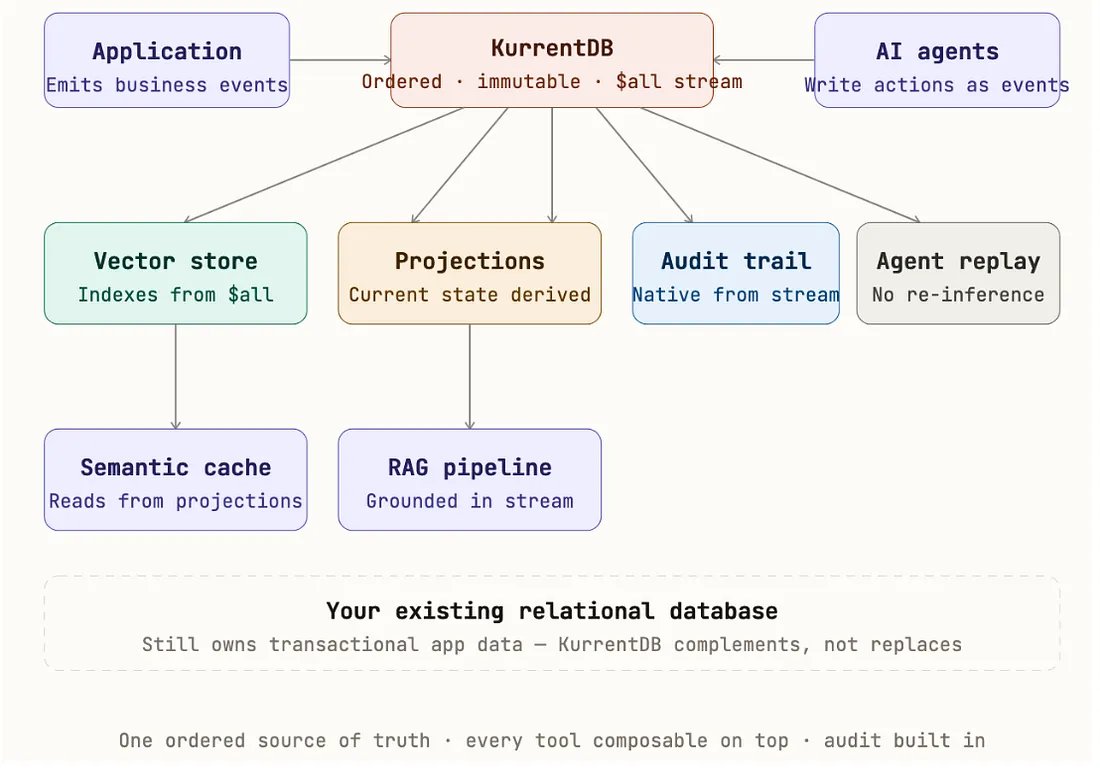
Consolidating Systems
Which Brings Me to What This Might Look Like Going Forward
At some point, the question has to change. Not: “How do I respond faster?” or “How do I reduce complexity?”
Those matter But they’re not foundational. The more important question is:
How do I ensure the AI is reasoning over what actually happened — in the order it happened — with a complete record of how it got there?
Or put another way — in the language everyone is using today:
How do I ensure the AI is working off real context, not just flattened data?
A Different Way to Think About It
If you start from that premise, the design shifts.
Events become the primary asset
Every meaningful change is captured first as an event. State isn’t stored as truth — it’s derived. You arrive at it. You don’t overwrite it.
History matters more than snapshots
The AI doesn’t just see what is true now. It sees how that truth was reached. The sequence. The causality. The context.
Replay replaces re-inference
When something fails — or needs to be understood later — you don’t re-run logic and hope for the same result.
You replay what already happened. No extra LLM calls. No cost spikes. No guesswork.
Auditability becomes natural
You don’t add logging later. The record is already there. Every decision can be traced back to what led to it.
And you’re not tied to one vendor
Events are just facts.They don’t belong to any system. They don’t depend on a specific API or framework. Which means everything else becomes replaceable.
The Vendor Lock-In Problem Nobody Talks About Until It Shows Up
Most architectures don’t feel locked in — until they are. Your cache depends on one system’s behavior. Your memory layer depends on a framework’s format. Your vector store becomes critical to how retrieval works. At that point, changing any one piece isn’t a swap. It’s a redesign.
If you’ve been around long enough, you’ve seen this before. A pricing change. An acquisition. A product shift that doesn’t align with your needs anymore. It happens. The real question isn’t if. It’s what happens when it does.
If your system is built around an event stream, that story changes. Because the stream doesn’t care what reads from it.
- Swap your model → the history stays the same
- Replace your vector store → nothing breaks
- Change your cache → no data migration
- Move cloud providers → the system still makes sense
The core of your system — what actually happened — stays with you.
The Questions Worth Asking
Before committing to any architecture, these are the questions I’d be asking:
When the AI gives an answer, can I trace exactly what it was based on?
When data changes, how does the system actually learn about it?
If something fails mid-process, can I replay it — or do I have to re-run it?
Am I simplifying the system… or just concentrating on the same limitation?
Can I explain how a decision was made — end to end?
If I change vendors tomorrow, what do I have to rebuild?
For some use cases, the answers may not matter.
Not every system needs full traceability or ordering. But if you’re working in areas where decisions have real consequences — financial services, healthcare, public sector — these questions tend to show up sooner rather than later.
Where This Leaves Me
Looking at the two patterns we started with — adding layers or consolidating systems — it’s clear the industry is moving. That’s a good thing. But the more I think about it, the more I feel like we’re still solving the problem. Not at the core of it.
Technology will keep evolving. The stack will keep changing. But the questions we need to answer haven’t really changed at all.
Can your system explain what it did? Not just what is true now. But how it got there?
Because once that history is gone — you don’t get it back.
