Secondary Indexes in KurrentDB: Default Indexes
KurrentDB v25.1 introduces secondary indexes, enhancing query performance and flexibility. This article explores the default secondary indexes provided by KurrentDB.
Motivation
Since the introduction of projections, KurrentDB (before EventStoreDB) has supported indexing events by using a special kind of log record called linkTo. This mechanism allows projections to create streams that contain links to events of a specific type, category, or a custom value, enabling efficient querying. Two system projections, $by_event_type and $by_category, have been available to facilitate this indexing, and custom projections could use the linkTo function to create additional indexes.
If you are not familiar with this feature, you can learn more how indexing worked historically in KurrentDB in Greg’s blog posts from back in 2013:
The last article about internal indexing specifically describes how the $by_event_type projection works. The default Category projection called $by_category works similarly, creating streams named $ce-{category} that contain links to all events in streams belonging to that category.
The initial release of secondary indexes in KurrentDB aims to replace those two system projections, effectively making them obsolete. So, you might ask why we are replacing a working solution with a new one? To answer that, let’s first look at how the previous generation indexing worked and what implications it has on performance and costs.
Indexing using linkTo records
Category and event type system projections, as well as custom projections that use the linkTo function, create additional log records in the database. Each linkTo record is a separate event that points to the original event. A linkTo record looks like this:
14@Order-342045Here, 14 is the event number of the original event in its stream, and Order-342045 is the stream ID of the original event.


linkTo records in a category stream
In addition, each linkTo record has metadata that is composed by the projection that produced it. All linkTo records have metadata in the same format, which looks like this:
{
"$v": "3:-1:1:4",
"$c": 51094534089,
"$p": 51094534089,
"$o": "Test-342045",
"$causedBy": "59072c4e-558a-405a-8025-13b48e20b8a3"
}Those properties are:
$v: a composition of the projection ID, epoch, version, and the projection subsystem version.$c: the commit position of the original event.$p: the prepare position of the original event.$o: the stream ID of the original event.$causedBy: the ID of the original event.
The content of that metadata is used by the projection to effectively track its progress and ensure that it can resume from where it left off in case of a failure.
When such a projection consumes an event that’s been persisted in the database, it creates a new linkTo record and appends it to the database log. In addition, the record is indexes in the default index. When both category and event type projections are enabled, each event written to the database results in two additional linkTo records being created, one in the category stream and another in the event type stream. This effectively triples the number of write operations being performed on the database.


Write amplification with linkTo records
When a stream of linkTo records is read, KurrentDB needs to read both the linkTo records and the original events they point to. This means that for each event you want to read from an index stream, KurrentDB performs two read operations: one for the linkTo record and another for the original event. In addition, KurrentDB might need to read the original stream’s metadata to ensure that the one who’s reading the linkTo records has the necessary permissions to read the original events, as well as to verify that original event is not considered “deleted” because of stream retention policies (truncation, max age, and max count). The stream metadata gets cached, however the nature of a series of linkTo records is that they can point to different streams, so cache hits are not guaranteed. Because the stream metadata cache is an LRU cache, the cache can start losing entries if there are many different streams being read via linkTo records, which is often the case for event type and category indexes. What’s worse is that the same cache is used for append operations, so heavy usage of linkTo records can lead to cache pollution, which can negatively impact write performance as well. Worst case scenario is that each linkTo read results in three read operations: one for the linkTo record, one for the original event, and one for the original stream’s metadata.


Read amplification with linkTo records
So, here we identify that projections that emit links effectively amplify the writes, something that is clearly mentioned in the documentation. On top of that, reading from those indexes is more expensive than reading from regular streams, as each event read requires multiple read operations. That’s why it isn’t uncommon to observe that a KurrentDB cluster that accepts 100 events per second in writes, shows around 460 write operations per second on the server side when all system projections enabled. In addition, if there are a few subscribers to those projection streams like category and event type, it’s not uncommon to see thousands or even tens of thousands of read operations per second on the server side, even when the application is only (explicitly) reading a few hundred events per second.
However, that’s not all. One thing we observed by looking at our customers’ databases is that when a system is well-designed to keep the database size contained by removing data that’s no longer required, the linkTo records tend to accumulate over time. This is because linkTo records are never removed when the original events are deleted due to stream truncation or retention policies. This happens because linkTo records are effectively events in projected streams, and KurrentDB only supports stream truncation, which deletes events from the beginning of a stream up to a certain point. So, if the original event is deleted due to retention policies, the linkTo record pointing to it remains in the index stream, leading to “dangling” links. Over time, this can lead to significant bloat in the database, as index streams accumulate linkTo records that point to non-existent original events.
This not only wastes storage space but also degrades read performance, as KurrentDB has to process these dangling links during reads. As an example, if you have a stream $ce-Order that contains 1,000,000 linkTo records, and 800,000 of those point to events that have been deleted due to retention policies, KurrentDB will still read all 1,000,000 linkTo records when you read from that stream. This means that 80% of the read operations are effectively wasted on processing dangling links. In case of replays, it can lead to significant delays, as the projection has to process a large number of dangling links before it can reach the relevant events.
Speaking of storage space, although linkTo records are relatively small, when counted in millions or billions, they can contribute to a significant increase in the overall size of the database. Let’s not forget that all the events are indexes by the default index, so linkTo records do not only contribute to the size of the main event log but also to the size of the indexes, which can further exacerbate storage issues.
Let’s look at some numbers from our early research on this topic. We created a dataset that contains 130 million events of around 250 bytes each, spread out across 1 million streams. System projections were stopped when the dataset was originally produced, so we can clearly measure the size of the database and the index without linkTo records in it.
| Description | Size (GB) |
|---|---|
| Main event log | 48 |
| Primary index | 3.2 |
| Total without linkTo records | 51.2 |
Then, we enabled all system projections, including $by_event_type and $by_category, and let them catch up. After that, we measured the size of the database again.
| Description | Size (GB) |
|---|---|
| Main event log | 102 |
| Primary index | 8.7 |
| Total with linkTo records | 110.7 |
As you can see, the size of the database more than doubled after enabling system projections, primarily due to the accumulation of linkTo records. In case the real dataset shrinks due to retention policies and proactive data deletion, the size difference would be even more pronounced, as linkTo records would accumulate even more.
Default secondary indexes
So, we clearly have an issue here. Index streams seemed like a good idea at a time, and we know that our users actively use category and event type streams to build their applications. However, the downsides of linkTo records are becoming more apparent as systems grow and evolve. That’s why we decided to introduce secondary indexes in KurrentDB v25.1, effectively providing a better alternative to the existing indexing mechanism based on linkTo records.
Considering that indexes are effectively collection of pointers to events, we needed to find a mechanism that would allow us to:
- Efficiently store those pointers without creating additional log records.
- Efficiently read those pointers without needing to read additional log records.
- Be able to remove those pointers when the original events are deleted due to retention policies.
- Support high write throughput without impacting the overall performance of the system.
- Be able to query those indexes efficiently.
As a result, we decided to use an embedded database called DuckDB to store the secondary indexes. DuckDB is an in-process SQL OLAP database management system that is designed to support high-performance analytical queries. It is optimized for read-heavy workloads and can efficiently handle large datasets. It is also optimized for ingesting data at high speed, because most of the analytical databases are dealing with immutable data that comes from external sources. Although it might seem counter-intuitive to use an analytical database for indexing in an event store, DuckDB’s architecture and performance characteristics make it a suitable choice for our use case. KurrentDB data is largely immutable and ordered, which aligns well with DuckDB’s strengths.
We also found out that DuckDB’s dictionary vector encoding is particularly well-suited for our indexing needs. Dictionary encoding is a technique where unique values are stored in a separate dictionary, and the actual data references these values using integer indices. This approach significantly reduces storage space and improves query performance, especially when there are many repeated values, which is often the case with event types and categories.
Finally, DuckDB queries work best on sorted columns, and KurrentDB’s event log is inherently ordered by commit position, which allows us to leverage this property for efficient indexing and querying.
How it works
First, we now have DuckDB embedded in KurrentDB nodes to store secondary indexes. Each KurrentDB node has its own DuckDB instance that manages the secondary indexes for the events stored on that node.
When an event is written to KurrentDB, in addition to appending it to the main event log, KurrentDB also updates the relevant secondary indexes in DuckDB. For default indexes, we use one table that includes both event type and category fields. Additionally, we store the log position (commit and prepare positions) of each event, which serves as a pointer to the original event in the main event log. We also decided to store less obvious information in the table, such as the stream ID, event number, and the event timestamp which can be useful for certain queries.
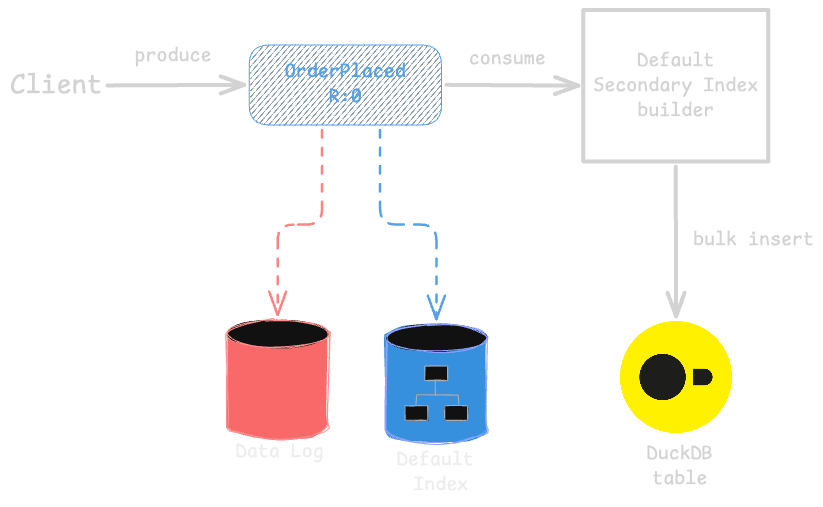
Writing to secondary indexes
When a query is executed that involves filtering by event type or category, KurrentDB translates this into a SQL query against the relevant DuckDB index. DuckDB then efficiently retrieves the pointers to the matching events, which KurrentDB uses to fetch the original events from the main event log. Unlike linkTo records, which point to an event number and stream ID of the linked event, index records point directly to the logical log position, so reading the actual events using index record doesn’t need to hit the default index. We had to adjust the default page size for subscriptions, which is 32 by default, as DuckDB performs better with larger batches. When we detect a read operation on a secondary index, we automatically increase the page size to 2000 for that subscription.
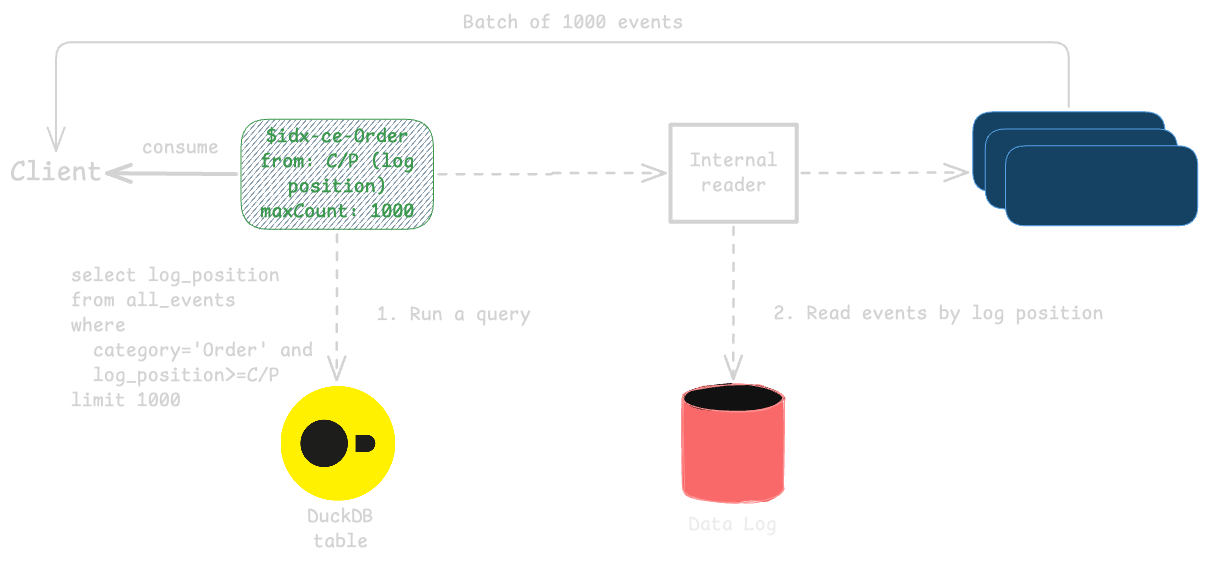
Reading from secondary indexes
It became obvious that we cannot fully support the same read and subscribe operations as before. That’s because indexes aren’t streams, there are no links, and there is no sequence number associated with each event in the index. But, we wanted to keep the existing API as much as possible.
To achieve compatibility with the existing client libraries, we decided to introduce a special kind of filter for operations that read from or subscribe to $all stream. Any client library supports this when the filter is set to a stream prefix filter with one value, which is the index name. Index names are composed similarly to stream names for linkTo records: $idx-ce-{category} for category index and $idx-et-{eventType} for event type index. For example, to read all events of type OrderCreated, you would read from $all stream with a stream prefix filter set to $idx-et-OrderCreated. Similarly, to subscribe to all events in the Order category, you would subscribe to $all stream with a stream prefix filter set to $idx-ce-Order. The primary difference is that instead of relying on the projected stream event number as a position, KurrentDB uses the log position of the events in the main event log, which is exactly how read/subscribe operations on $all stream work.
New numbers
Let’s compare how our measurements look like with secondary indexes enabled instead of linkTo records.
First, the dataset size:
| Description | Size (GB) |
|---|---|
| Main event log | 48 |
| Primary index | 3.2 |
| Secondary indexes (DuckDB) | 2.2 |
| Total with secondary indexes | 53.4 |
As you can see, the size of the database with secondary indexes is only slightly larger than the original size without any indexes, and significantly smaller than the size with linkTo records.
What I didn’t mention previously is that after producing the test dataset, I enabled system projections to get the linkTo records created. Let me remind you that the dataset contains 130 million events spread across 1 million streams. After enabling all system projections, the time it took to process all events was around 10 hours. I must admit that I was a bit surprised by how long it took, but considering the number of read and write operations involved, it makes sense.
When building the secondary indexes feature, rebuilding the index on a large dataset became quite a routine task. I rebuilt the index multiple times during development, and each time it took around 40 minutes to process all 130 million events. This is a significant improvement over the previous approach using linkTo records.
When it comes to read performance, I measured both regular reads and subscriptions. Probably, subscriptions performance is the most important metric for this blog post as the primary use case for linkTo streams was to support projections and subscribers. Our tests repeatedly showed the read speed fluctuating between 3 and 5 thousands events per seconds when reading from linkTo streams. With secondary indexes, the read speed consistently reached around 40,000 events per second with multiple subscriptions running simultaneously, which is a substantial improvement. Of course, there’s a caveat here: the current implementation of this feature uses the read API on $all stream which is only allowed for admin users, so the authorization checks aren’t performed, and it definitely contributes to the improved performance. However, even when accounting for that, the performance improvement is still significant.
Side effects
Because now we have all the events indexed in a DuckDB table, it was quite trivial to add new features that leverage this index. Those features were originally not in scope of the feature implementation, but we have seen great success of those features in our internal testing, so we decided to include them in the initial release.
First, we added the database Stats page to the new embedded UI, which shows how many streams, categories, and event types are present in the database. It also shows which even types are used in which category, and how many events of each type are present in each category. This information was not easily accessible before, and now it’s just a matter of querying the DuckDB index. We also show when an event of each type was first and last added to the database. This way, you can see what event types are no longer in use and can be potentially removed from the application code.
We were also able to introduce a preview of exploratory queries in the embedded UI. You can now run ad-hoc queries against the data stored in KurrentDB. Using an inline function for DuckDB, you can now query events by type, category, stream ID, time range, and even event data content. This feature is still in its infancy, but we are excited about the possibilities it opens up for users to explore their data directly within KurrentDB.
What comes next
Default indexes replacement is just the first step in our journey to improve indexing in KurrentDB. We are already working on adding support for custom secondary indexes, which will allow users to define their own indexes based on specific event data fields. This will provide even more flexibility and performance improvements for querying events.
In addition to that, we plan to look into further enriching the query capabilities, allowing read and subscribe operations to filter by multiple predicates, combining event type, category, time range, and even event data content. This will make it easier for users to retrieve exactly the events they need.
So, watch this space for more updates on indexing in KurrentDB!
