LangGraph Checkpointer on KurrentDB
Overview
KurrentDB is well-suited for agentic workflows thanks to its append-only storage of every state transition as events in streams. This approach ensures a complete historical record, enabling reconstruction of any process or entity’s journey, unlike CRUD systems that only retain the latest state. This article illustrates how KurrentDB can serve as a LangGraph checkpointer, enhancing observability even for internal checkpointing processes in complex agentic systems.
If you are already familiar with how KurrentDB works, you can skip to how LangGraph works, how KurrentDB can be used to solve checkpointing problems, and the associated Python Notebook below or in our examples folder.
What is KurrentDB?
KurrentDB is a database that is engineered for modern software applications and event-driven architectures. Its event-native design simplifies data modeling and preserves data integrity, while the integrated streaming engine solves distributed messaging challenges and ensures data consistency.
How is data stored in KurrentDB?
Data is append-only stored and read as events from streams. For example, the following diagram shows a stream of business facts, stored as events, related to a shopping cart. This is an easy way to map state transitions.
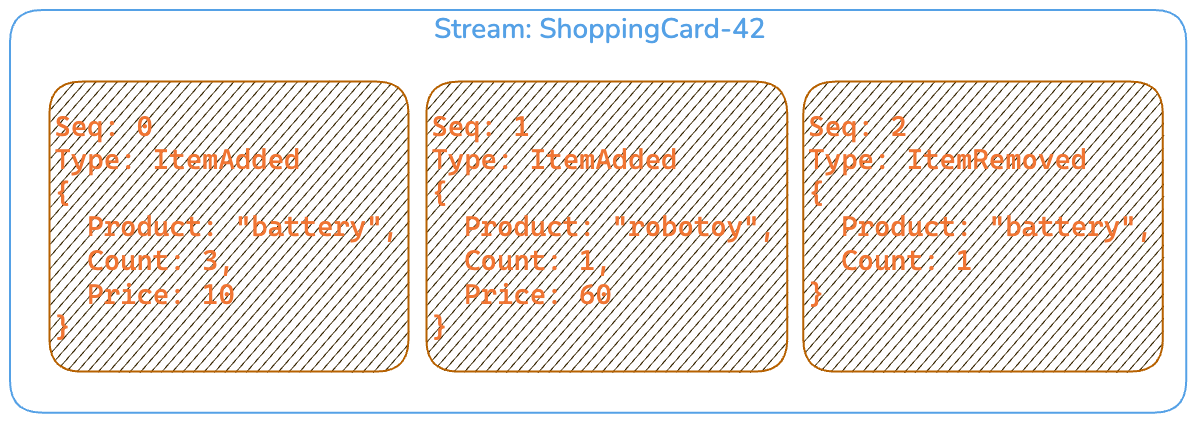

History of state changes as events
With the stream above you can replay the events to reach the final state of your cart, in this case two batteries and one Robotoy. The advantage with keeping every state transition is that contrary to CRUD, where you would only have the last state after an update, you now know that a user had previously added three batteries and then later removed one battery.
How is data indexed in KurrentDB?
In KurrentDB the index is over the stream names so accessible streams are efficient and it is encouraged to create as many fine-grained streams as possible. This is why all the channel values (nodes and state) have their own dedicated stream. If you had to estimate the number of streams created for your LangGraph graph, you need to account for the thread, all nodes and state variables. This allows you to subscribe to the streams and keep track of changes live if you wish to do that.
Concurrency control is available to handle dual write problems faster than other databases thanks to an internal cache on streams and the way the internals are built.
What is LangGraph?
LangGraph is an orchestration framework for complex agentic systems. At its core, LangGraph models agent workflows as graphs made up of States, Nodes and Edges and a messaging system inspired by Google’s Pregel System.
LangGraph’s underlying graph algorithm uses message passing to define a general program. When a Node completes its operation, it sends messages (as Channels) along one or more edges to other node(s).
The checkpointer is responsible for storing those channels and state. LangGraph ships with in- memory, SQLite and PostgreSQL implementations of the checkpointer. However, you can find other third party checkpointers in PyPi.
Using KurrentDB to checkpoint LangGraph
Given the properties above, we thought that it would be interesting to see how well KurrentDB would fit as a checkpointer for LangGraph. Because at the end of the day, LangGraph needs to manage Channels and State and this maps particularly well to KurrentDB given its qualities to persist state transitions.
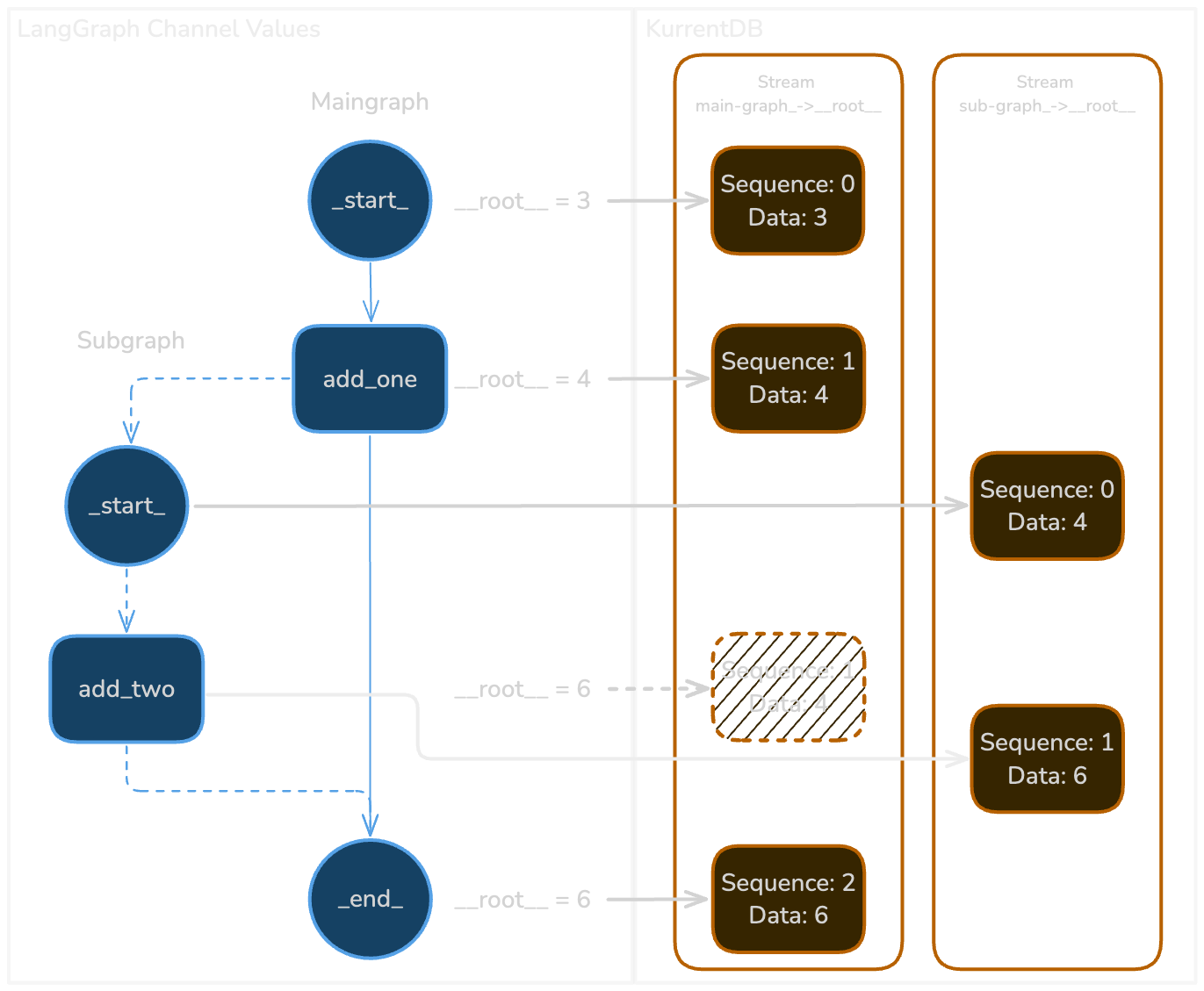
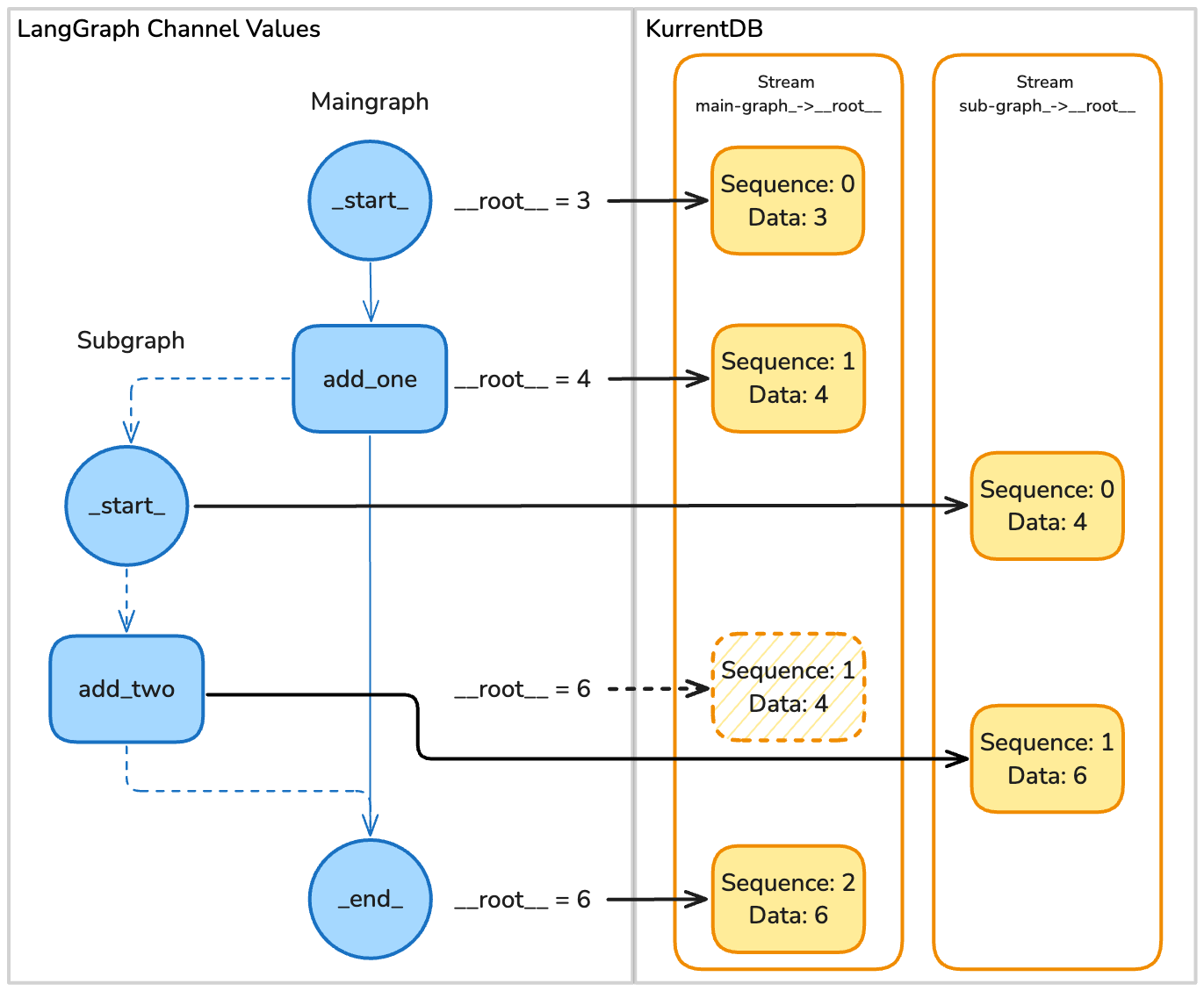
Mapping steps (top to bottom) from LangGraph to KurrentDB
Threads
Every run is associated with a unique thread id. The thread id is mapped to a stream in KurrentDB. Every step along the graph is logged as an event of type langgraph_checkpoint. The format of the stream name is thread-{thread id} for example a thread with id test-run-1 would map to a stream name called thread-test-run-1.
With the category projection enabled this allows us to list everything thread related inside the $ce-thread stream or with the by_eventType projection to list everything checkpointing related inside the $et-langgraph_checkpoint stream. This is useful to track all the runs happening in your application.
TIP
A projection in KurrentDB can be thought of as an ongoing read and write in the system based on a rule or code. In this case, we are reading for streams with a format of thread-{thread-id} and grouping them (pointers) into a $ce-thread stream. You can read more about projections in the database documentation.
Example Graph with a Subgraph
This is saved as a series of events inside the thread-main-graph stream:
#Establish connection to KurrentDB
kdbclient = KurrentDBClient(uri="insert connection url here")
memory_saver = KurrentDBSaver(client=kdbclient)
config = {"configurable": {"thread_id": "main-graph"}}
# Main graph
builder = StateGraph(int)
builder.add_node("add_one", lambda x: x + 1)
builder.set_entry_point("add_one")
# Subgraph
subgraph_builder = StateGraph(int)
subgraph_builder.add_node("add_two", lambda x: x + 2)
subgraph_builder.set_entry_point("add_two")
subgraph_builder.set_finish_point("add_two")
subgraph = subgraph_builder.compile(checkpointer=memory_saver)
builder.add_node("subgraph", subgraph)
builder.add_edge("add_one", "subgraph")
builder.set_finish_point("subgraph")
graph = builder.compile(checkpointer=memory_saver)
# Test execution
result = graph.invoke(3, config)
assert result == 6 # 3 + 1 + 2 = 6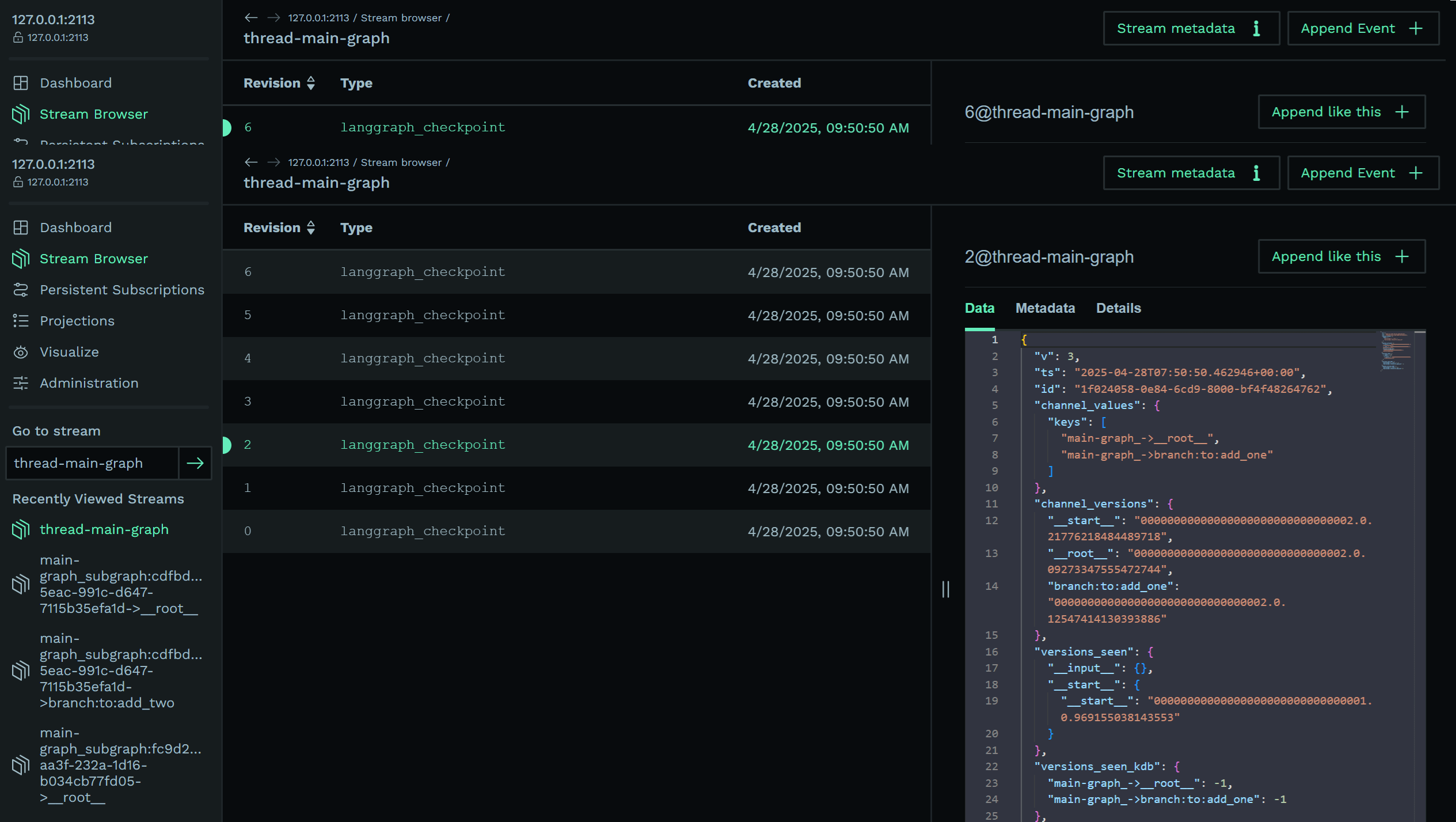
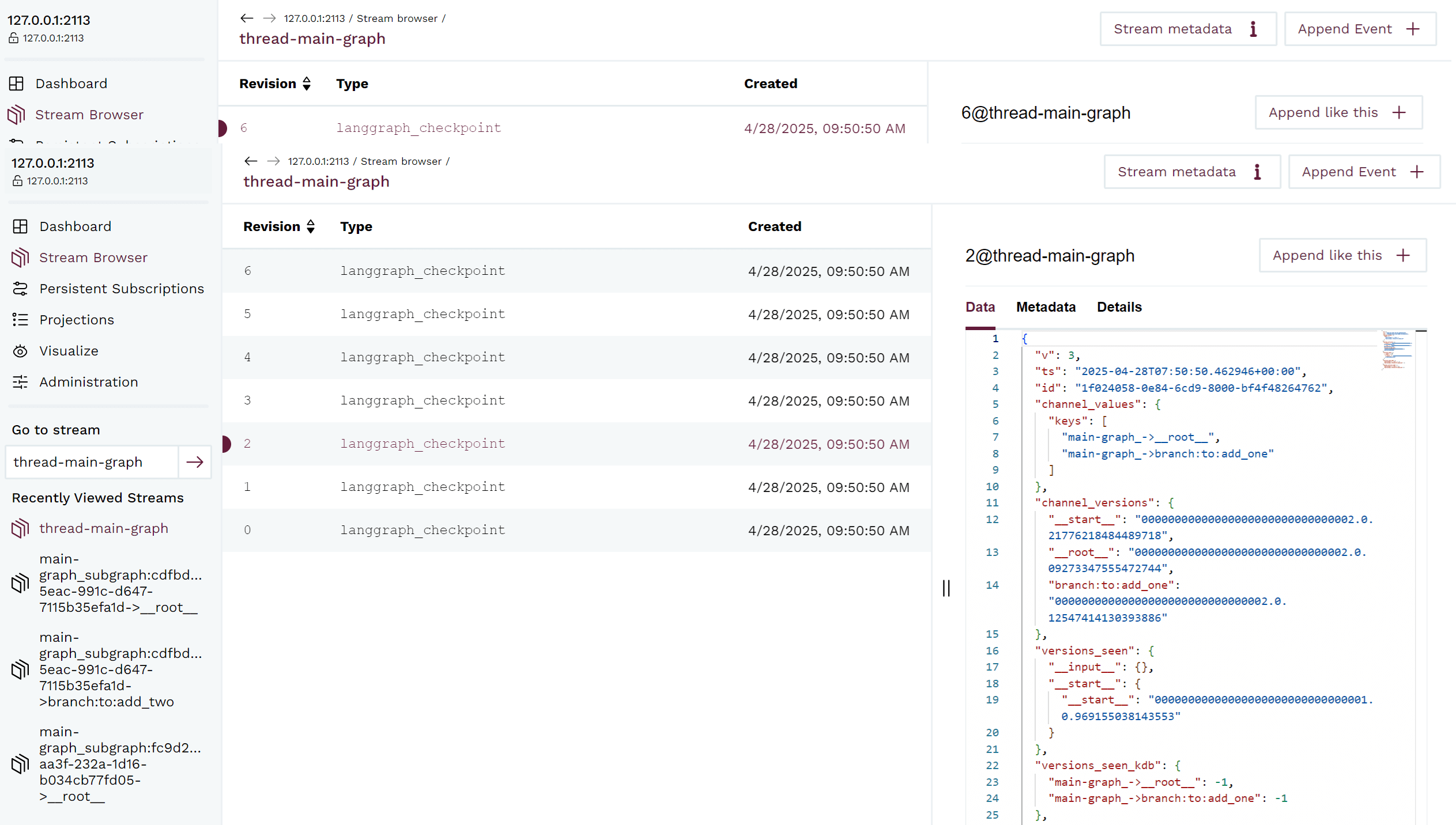
Stream Browser Image
Channel Values
Channel Values contain the payload for the Channels in LangGraph which contain the messages from nodes and edges after completion of an operation.
Every Event has a Data and Metadata section in KurrentDB. A pointer to a different stream for every Channel value is kept. By having a separate stream for every Channel Value we can keep track of changes/transitions for every small state in the entire graph.
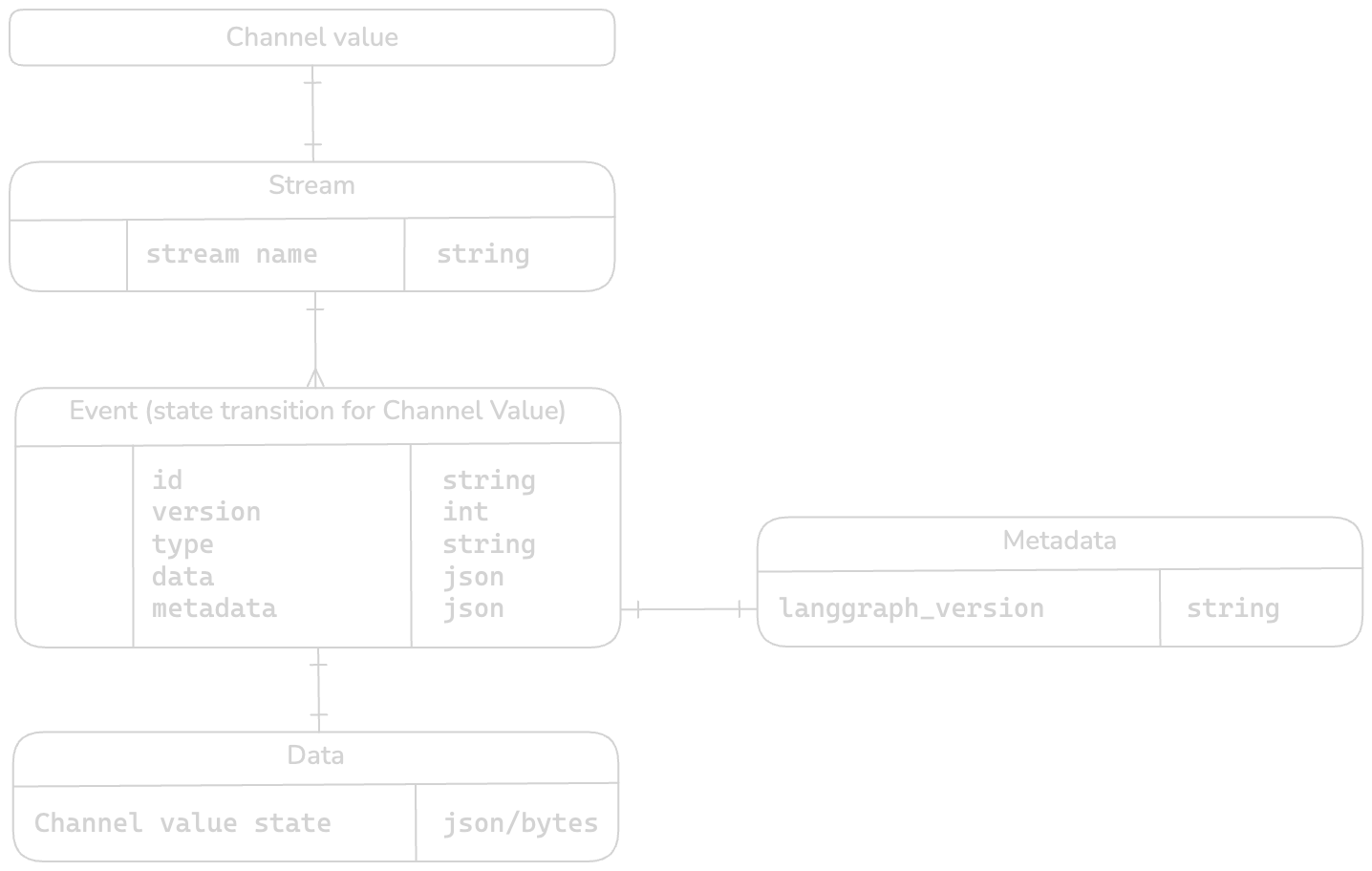
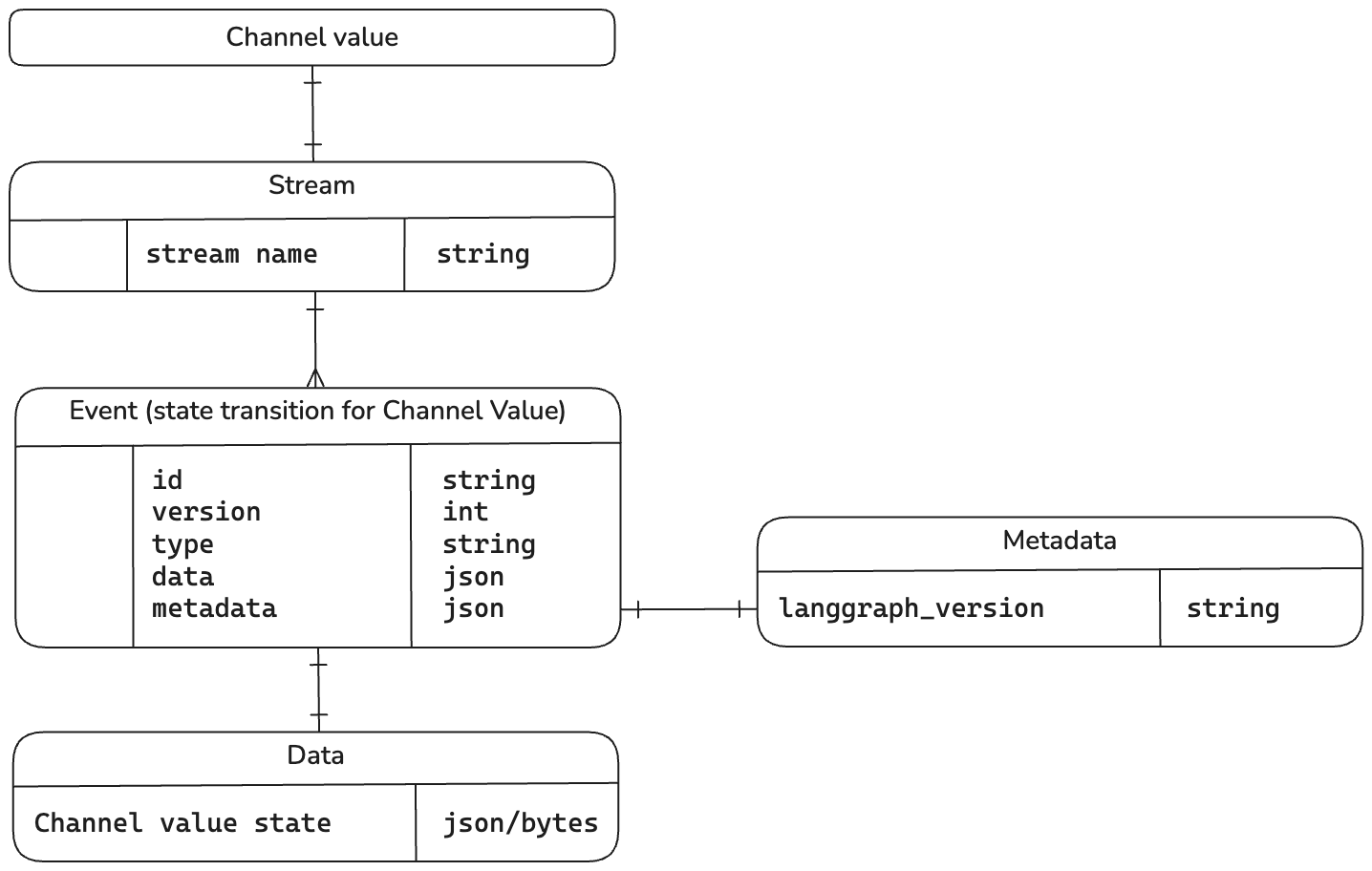
Mapping ER diagram
For example if we expand the third event 2 in the graph, we see that there is a pointer to stream main-graph_->__root__ and 0 as the version of that stream in the channel_versions_kdb, which points to the first event of the stream.
// Data
{
"v": 3,
"ts": "2025-04-28T07:50:50.462946+00:00",
"id": "1f024058-0e84-6cd9-8000-bf4f48264762",
"channel_values": {
"keys": [
"main-graph_->__root__",
"main-graph_->branch:to:add_one"
]
},
"channel_versions": {
"__start__": "00000000000000000000000000000002.0.21776218484489718",
"__root__": "00000000000000000000000000000002.0.09273347555472744",
"branch:to:add_one": "00000000000000000000000000000002.0.12547414130393886"
},
"versions_seen": {
"__input__": {},
"__start__": {
"__start__": "00000000000000000000000000000001.0.969155038143553"
}
},
"versions_seen_kdb": {
"main-graph_->__root__": -1,
"main-graph_->branch:to:add_one": -1
},
"channel_versions_kdb": {
"main-graph_->__root__": 0,
"main-graph_->branch:to:add_one": 0
}
}
// Metadata
{
"source": "loop",
"writes": null,
"step": 0,
"parents": {},
"thread_id": "main-graph"
}
You will notice that we also keep the usual Channel Versions on top of our own KurrentDB versions for compatibility. If you go to the main-graph’s __root__ stream you will see its stored value in the data (3,4,6) and the mapping done in the event metadata.
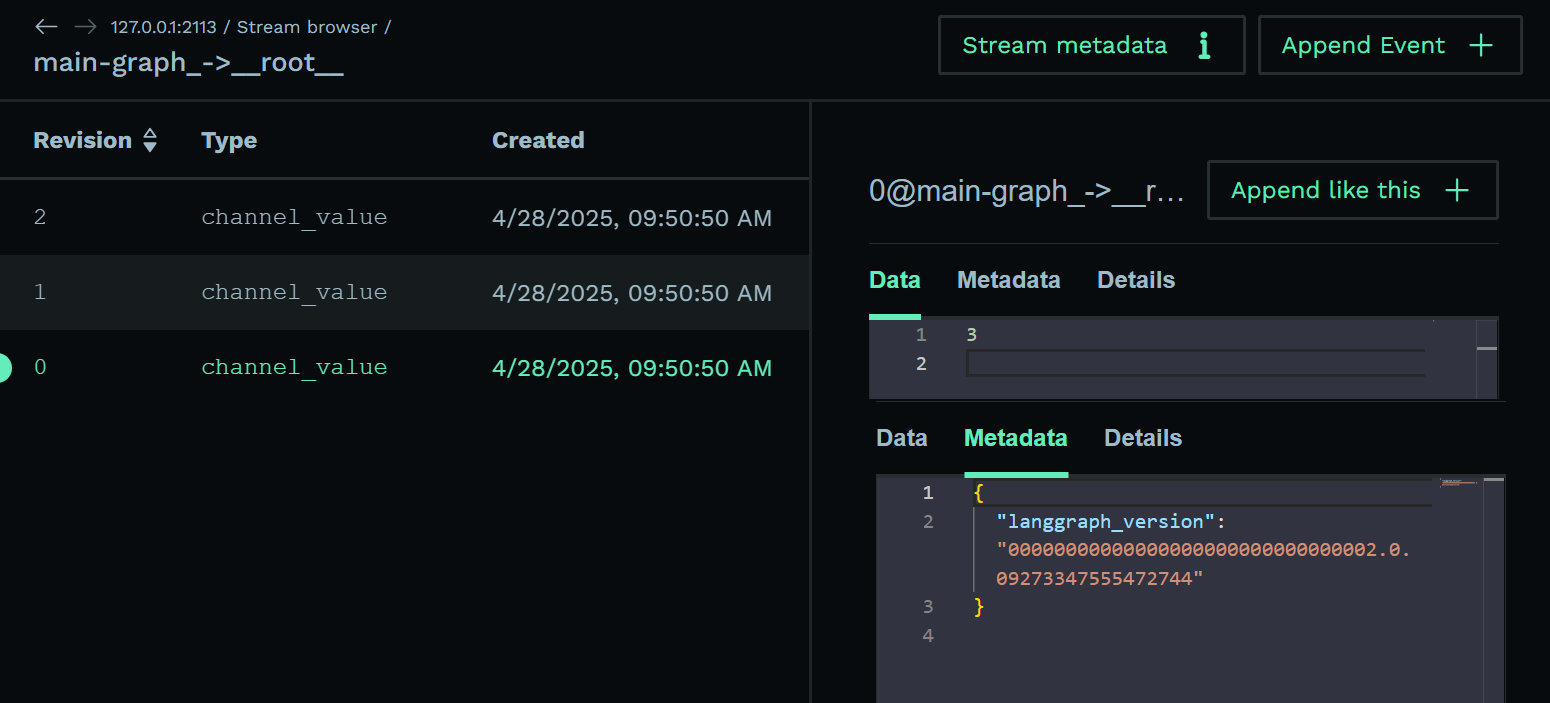
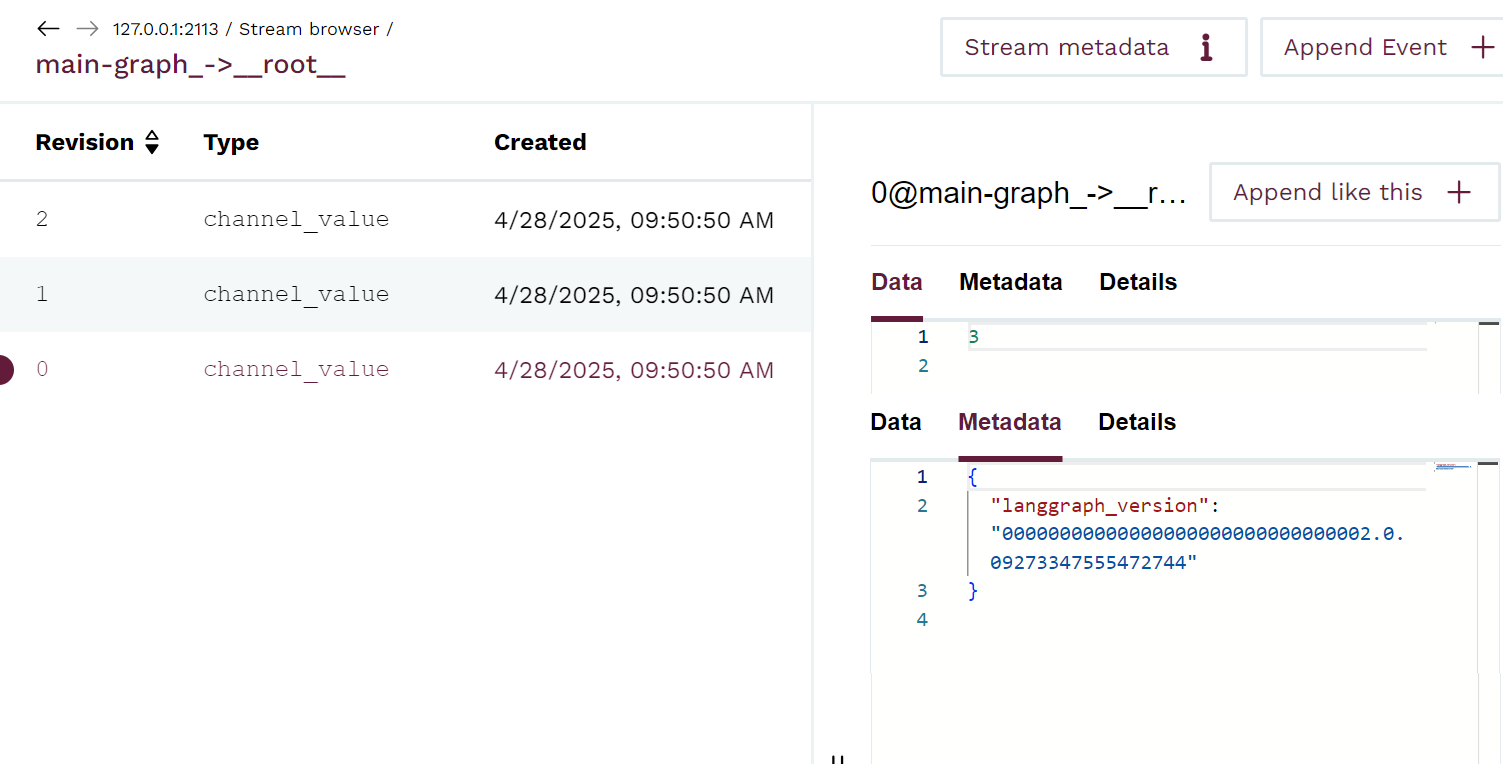
main-graph-root Stream
Observability
We have added another feature not present in other checkpointers to export trace of a particular thread to tracing platforms supporting OpenTelemetry. We can do this efficiently by reading through the thread stream and rebuilding the series of events (literally) that happened into a trace. Every event written in KurrentDB already has a timestamp which we can use to determine the time taken for every step. We have provided a Python Notebook to make it easier to get started with the checkpointer. The end result should look like the screenshot below in Jaeger:

Full Code Python Notebook
This is a simple example where we add a decorator to wait a random amount of time between 1 and 3 seconds. For example when get_weather is called by LangGraph a random amount of time is awaited. This makes the trace more interesting.
from kurrentdbclient import KurrentDBClient
from langgraph.graph import StateGraph
from typing import Dict
from langgraph_checkpoint_kurrentdb import KurrentDBSaver
# wait a random amount of time
import random
import time
def random_delay(func):
def wrapper(*args, **kwargs):
time.sleep(random.randint(1, 3))
return func(*args, **kwargs) # Call the original function
return wrapper
# Simulated weather function
@random_delay
def get_weather(location: str) -> Dict:
# Replace with real API call
weather_data = {
"Luxembourg": {"temp_c": 8, "condition": "Rainy"},
"Barcelona": {"temp_c": 22, "condition": "Sunny"},
}
return weather_data.get(location, {"temp_c": 15, "condition": "Cloudy"})
# Decision logic
@random_delay
def clothing_advice(weather: Dict) -> str:
temp = weather["temp_c"]
condition = weather["condition"]
if temp < 10:
return f"It's {condition} and cold. Wear a coat and bring an umbrella."
elif temp < 20:
return f"It's {condition} and cool. Wear a light jacket."
else:
return f"It's {condition} and warm. Shorts and t-shirt are fine."
# Simulated logger
@random_delay
def log_advice(advice: str) -> str:
print(f"[LOG] Advice: {advice}")
return advice
#Establish connection to KurrentDB
#Sign up for Kurrent Cloud at https://www.kurrent.io/kurrent-cloud to get a connection string
#Note that you will need a projections enabled cluster/single node
kdbclient = KurrentDBClient(uri="Insert connection string here")
memory_saver = KurrentDBSaver(client=kdbclient)
# Building the graph
builder = StateGraph(str) # Initial state is a location name (str)
builder.add_node("get_weather", get_weather)
builder.add_node("clothing_advice", clothing_advice)
builder.add_node("log_advice", log_advice)
# Setting up flow
builder.set_entry_point("get_weather")
builder.add_edge("get_weather", "clothing_advice")
builder.add_edge("clothing_advice", "log_advice")
builder.set_finish_point("log_advice")
config = {"configurable": {"thread_id": "weather-graph"}}
# Compile and run
graph = builder.compile(checkpointer=memory_saver)
result = graph.invoke("Luxembourg", config)
# Export to OTEL
# docker run --rm --name jaeger -p 16686:16686 -p 4317:4317 -p 4318:4318 -p 5778:5778 -p 9411:9411 jaegertracing/jaeger:2.5.0
# pip install opentelemetry-api
# pip install opentelemetry-sdk
# pip install opentelemetry-exporter-otlp
from opentelemetry import trace
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
memory_saver.export_trace(thread_id="weather-graph", span_processor=span_processor, trace=trace)Next Steps
This experimental integration demonstrates the potential for using Kurrent event-native database in orchestrated AI workflows. If you would like to see the checkpointer as a supported product you can provide feedback on GitHub.
