

By: Vaughn Vernon
Adapting my Implementing Domain-Driven Design AgilePM Example to TypeScript using KurrentDB running serverless with DomoActors and DomoTactical
Introduction
Many who are interested in Domain-Driven Design (DDD) have read my book, Implementing Domain-Driven Design (IDDD).[1] At the time of writing, Java and C# running on servers was an industry mainstay. While writing, cloud computing had begun to make inroads, but it was not as widely adopted by that time as it has become. Even if companies were deploying to the cloud, serverless as we know it was not available until November 13, 2014 when AWS introduced AWS Lambda. [2] By that time, IDDD had been available online for more than two years and in print for nearly two years. Yet, at this time, serverless computing is a true commodity and many consider fully-managed services to be the only way to fly.[3]
Event Sourcing and CQRS were gaining ground. One reason was the availability of a new product: EventStore. This Event Sourcing database later became known as KurrentDB.
Using TypeScript and KurrentDB
Even more to the point, TypeScript is one of the most prevalent programming languages capable of running serverless. Transpiled to the JavaScript language and executed on a JavaScript runtime engine, TypeScript offers a statically-typed language with many modern capabilities for both functional-style and object-oriented programming. Written very generically, it could easily remind you of Java and C# if you squint a little.
My IDDD book introduces two architecture patterns known as Event Sourcing and CQRS, and provides some implementation examples. I'll explain more about the Event Sourcing and CQRS patterns below. To be sure, KurrentDB is a major player in this territory.
The actual running code examples that I provided on my GitHub account when IDDD was published back then use various persistence approaches, including object-relational mapping (ORM), key-value (KV) storage, and Event Sourcing.[4] The idea was to show that ORM wasn't the only game in town, even though it was the most popular at the time of publication. In particular, the Agile Project Management Context (DDD Bounded Context, called AgilePM for short) example code on GitHub uses Event Sourcing.
What I didn't use at the time was a commercially supported Event Sourcing database. That changes here, and Figure 1 introduces a primary member of main cast of the architecture.
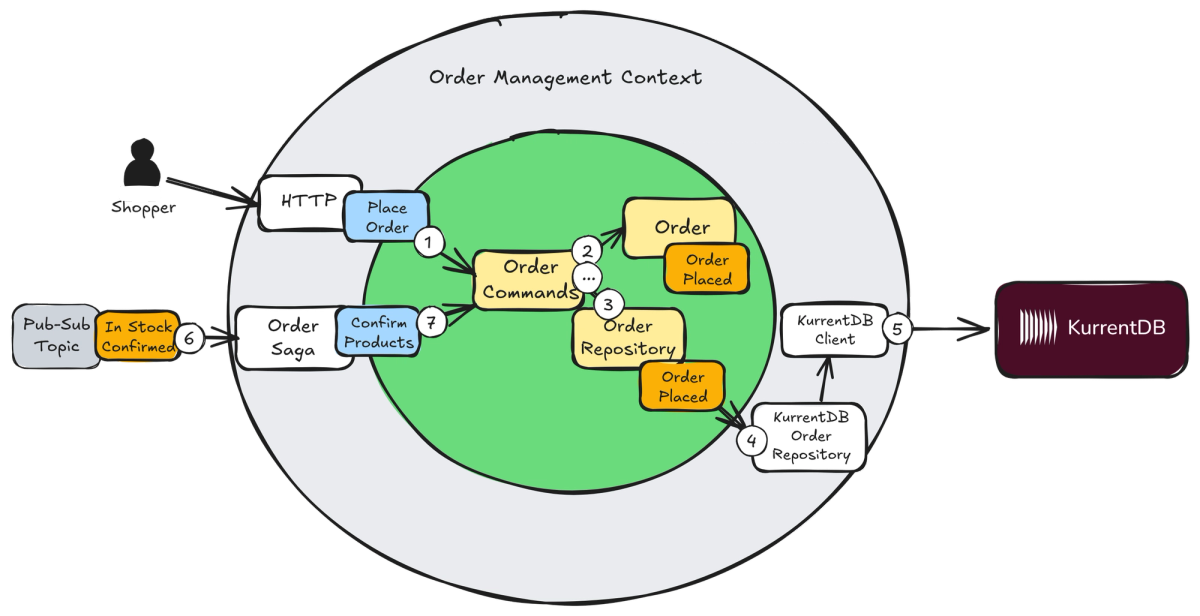
Figure 1: KurrentDB provides an advanced Event Sourcing database that snaps into your architecture.
Figure 1 shows a Ports and Adapters Architecture (previously named Hexagonal) for an order management system (a general-purpose service example not discussed in IDDD). To understand the process flow, follow the numbered steps. The circled ellipsis represents steps that continue after step 7 onward.
To the right of this Bounded Context are the essential components supporting KurrentDB. Two driven-side adapters are the supporting cast: (a) the OrderRepository implemented for KurrentDB that is responsible for persisting Order object events; (b) the KurrentDBClient library that provides remote access to the database. The KurrentDB itself is the component represented by the maroon rectangle farthest to the right.
To set some context, KurrentDB is the premiere, purpose-built Event Sourcing database. It became publicly available in 2012, slightly after IDDD was published online and a few months before IDDD was published in print. I am using KurrentDB for the example that I provide in this article, which is a re-implementation of the AgilePM Context running serverless, using TypeScript and KurrentDB. For more information on advanced enterprise features, see the penultimate subheading: Going Enterprise.
If you are using or plan to use Event Sourcing and CQRS, KurrentDB deserves your serious consideration. If it's not already intuitively obvious why, you'll learn as this article series progresses.
Technology Stack: KurrentDB, DomoActors, and Cloudflare Serverless
You can find a reference in IDDD to the Actor Model and how actors can be used. (I did much more with actors following the book's publication.) Actors are objects, but objects that receive messages asynchronously from client objects or actors rather than direct method calls/invocations.
An actor message is handled by the actor in the order received in its mailbox. Messages are handled one at a time, which prevents race conditions on the state of an actor instance. The actor's state is not shared and remains protected from the outside because actors use a messaging protocol established for themselves. The protocol is designed to protect the actor's state. My DomoActors open-source library supports the declaration and implementation of TypeScript interfaces as protocols. Thus, all messages are type-safe. You'll find all Domo libraries on my GitHub account.[5]
Asynchronous messaging doesn't necessarily produce parallel processing. In the single-threaded JavaScript environment, asynchronous-based concurrent processing is available using collaborative/cooperative approach. It's supported by the async and await keywords that are used for task switching in specific situations, such as when I/O would normally cause the thread to block. In the case of blocking I/O, JavaScript runs the next task on its queue and only continues the task waiting for I/O when the I/O completes.
I've accomplished actor-based asynchronous messaging using a combination of JavaScript dynamic proxies to create messages from intercepted function/method calls, along with async/await. This transitions JavaScript's single-threaded nature into yielding, non-blocking asynchronous messaging that gives the illusion of concurrency. These basic Actor Model facilities are provided by DomoActors.
As an add-on, DomoTactical is another open source library that offers the most commonly used DDD tactical patterns, including Aggregates and Domain Events. (This is a newish library and more support will be included in time.) There's also support for Event Sourcing and CQRS. The Event Sourcing persistence using KurrentDB is built into the EventSourcedEntity abstract base class that serves as a root entity actor for Aggregate types. Because persistence is built-in and imperceptible, the Repository pattern seen in Figure 1 is unnecessary and unused.
Note
To be clear, use of the Actor Model is not a necessity to employ Event Sourcing, CQRS, or KurrentDB, for that matter. Rather, it is an architectural choice. You can instead use common JavaScript or TypeScript programming conventions without involving actors. The same goes for other languages such as C# and Java. Still, I find that thinking in actors helps me to reason about what the software does and how it works.
Additionally, DomoTactical supports routing to CQRS projection; that is, query model pipelines are available. All of these tools extend the Actor abstract base type, which is the linchpin for the Actor Model provided by DomoActors. Figure 2 shows the relationship between the Domo libraries and KurrentDB.
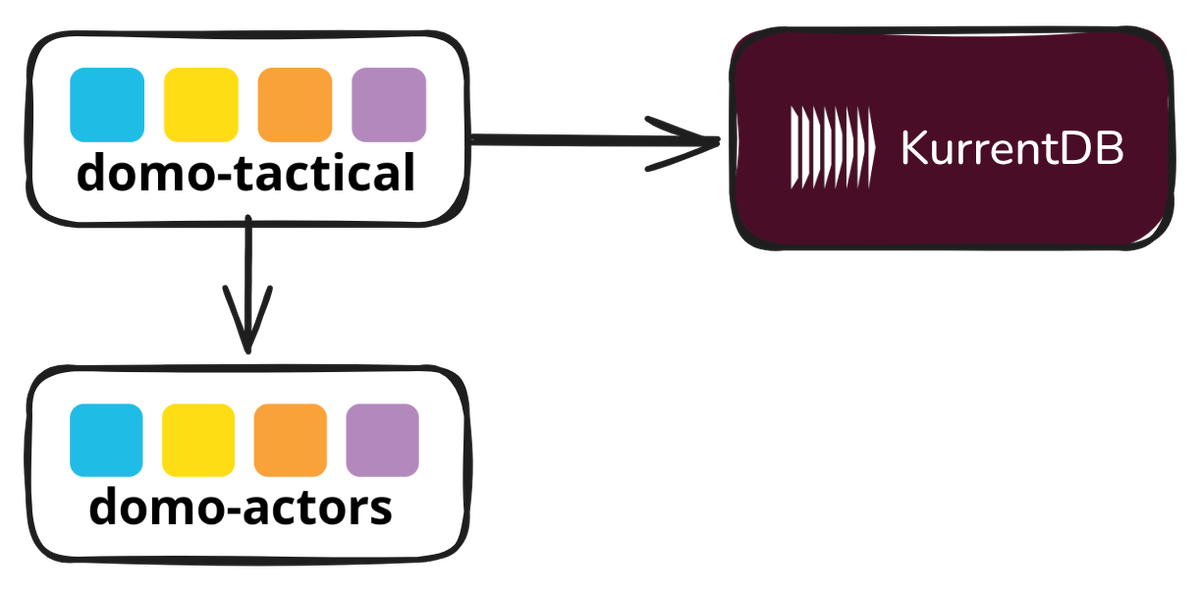
Figure 2: The major components of the AgilePM example.
Being a set of abstractions, DomoActors and DomoTactical don't natively support KurrentDB as the only storage mechanism, but offer the same patterns as abstractions. There's a general-purpose Journal protocol. Thus, this example has a JournalAdapter to enhance the KurrentDBClient—part of the KurrentDB distribution—to be actor-based. I think this is worth demonstrating specifically because you'll likely be introducing KurrentDB into your systems with unrelated libraries or frameworks that are already heavily in use. This is intended to demonstrate a realistic integration challenge that's rather easily solved.
Finally, the runtime is on Cloudflare using its serverless Workers components. Workers are used for REST services request handling, Pages dynamic and static websites, Durable Objects, message queue delivery, cron scheduled timer signaling, object and KV storage, etc. TypeScript Workers run on vanilla the V8 JavaScript engine with a rich set of shims to emulate Node.js in the lightweight serverless environment.
When Things Go Wrong
All this considered, how can persistence be imperceptible when something goes wrong, such as a network partition or a downed remote component such as a database? Won't an exception be thrown and leak persistence into the application?
One of the least well-known and underappreciated features of the Actor Model is actor supervision. Every actor has at least a default supervisor automatically assigned by the actor scaffolding. Typically, though, specific actor types are assigned specific supervisors, specially designed to deal with the kinds of failures common to that actor type. A Journal can, for example, have the DefaultJournalSupervisor, or a special one that is more tuned to KurrentDB. The point of supervision is that error handling is largely separated from main service/application flow. Supervision too can be imperceptible and still prevent both normal a catastrophic failures.
You might be tempted to consider supervision among the chief reasons to use the Actor Model. You wouldn't be wrong.
Kinds of Protocols and Actors
Every actor must have a protocol. The protocol is the "language" that the actor speaks. If using DDD, the actor will "speak" some subset of the Ubiquitous Language.
DomoActors enables type-safe protocols through the use of TypeScript interfaces. To declare an actor protocol, define the protocol name and its method/function signatures.
When using Event Sourcing we tend to segregate two different kinds of protocols: commands and queries. It's not absolutely necessary to do this, but it is by far the most common architectural approach.
If the actor offers commands in its protocol, command signatures are declare on the protocol interface. If the actor supports answering queries/questions, the protocol interface will declare one or more query methods.
The differences will become clearer in the following subsections.
Before diving deeper into the AgilePM problem space, Event Sourcing and CQRS need an introduction. First up is Event Sourcing followed by CQRS.
Event Sourced Aggregates
Event sourcing is used for a few primary reasons, which are illustrated in Figure 3.
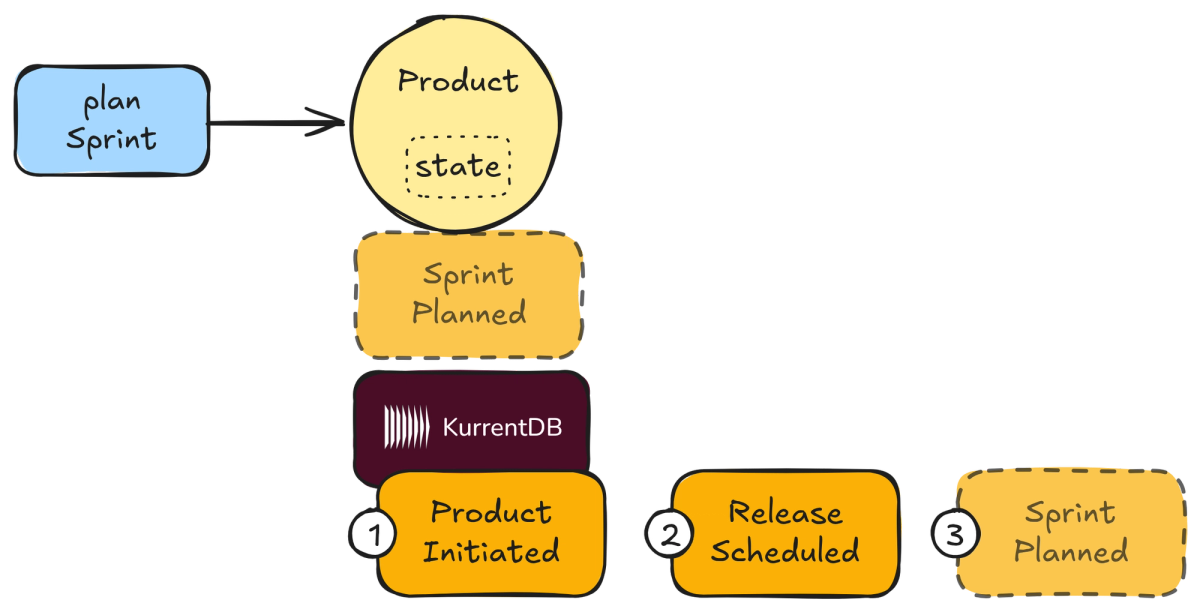
Figure 3: A simple introduction to Event Sourcing.
Note
I like to distinguish actors from plain objects by drawing them as circles rather than rectangles.
Figure 3 shows command handling by a Product. The initiate() command has already occurred, as has scheduleRelease(). This is apparent because (1) ProductInitiated and (2) ReleaseScheduled have already been persisted in KurrentDB. The Product is now about to handle the planSprint(). The SprintPlanned event is dimmed with a dashed border to indicate it is about to happen and persistence will soon occur.
The following list breaks down what Event Sourcing is along with what has happened and is yet to happen in Figure 3. Also, take note of the reasons to use Event Sourcing that are weaved into the list.
- A stream (ordered collection) of events is used to represent some partial, discreet state of the system. There is such a stream for each individual state that is persisted. This state might belong to a single aggregate instance, which is true of the
Productinstance in Figure 3. (This is later refactored and the second and third events become part of two additional separate streams.) This is a partial state—only part—of the whole system because it represents just a small part of the full AgilePM state. - When an incoming behavioral request (command) to the aggregate arrives, an event is created to represent the corresponding change—a fact indicating what happened. The event's type and properties are a single factual historic record of a change. A given command could be rejected, in which case no event would be created. The
planSprint()command message is about to be handled and the SprintPlanned event is about to be applied and persisted to KurrentDB. - It is possible that a single command will cause multiple events to be created, but a single event is typical. Applying multiple events as a result of handling one command is not illustrated in Figure 3.
- As each new event is created it is applied to the existing state—or a completely new state when the Aggregate is first created—and the event is persisted. This causes the transition from the current state (undefined when new) to the next state. The
stateof theProductrepresented in Figure 3 within the Aggregate boundary. - Every event remains in the persistent stream in the order in which it occurred. When a full state must be reconstituted, the persistent stream is reapplied to bring the state back to its current version. Figure 3 indicates by sequence number what occurred first, second, and will occur as the third historic record.
- State reconstitution takes place by flattening the stream into a single accumulator (a state). Each event causes a change to the state is it did in point 3. After all events have been applied to the state, the state it considered current with the stream.
- Collectively, all state-representing event streams are ordered in one overarching stream by occurrence sequence for the entire Bounded Context in which the aggregates reside. This "all" stream can be used to inform interested parties of specific occurrences both inside and outside the Bounded Context.
Note
KurrentDB appropriately uses the name *$all* for this overarching stream of all persisted facts.
Although I don't include points 6 and 7 in Figure 3, these will become clear in the source code review in both this article and in subsequent ones.
CQRS
Consider two kinds of operations that are common to software behaviors: commands and queries. Table 1 has some examples of commands and queries.
| Type | Example | Description |
|---|---|---|
| Command | `requestDiscussion(...): void` | Requests that a collaborative forum discussion be started. |
| Query | discussionOf(id): DiscussionData | Asks for specific discussion view data including its post threads. |
| Command | planSprint(...): void | Plans a new Scrum sprint. |
| Query | sprintOf(id): SprintData | Asks for specific sprint view data. |
| Command | scheduleRelease(...): void | Schedules a new Scrum release. |
| Query | releaseOf(id): ReleaseData | Asks for specific release view data. |
Table 1: Examples of commands and queries related to the commands.
In Table 1 note that the two distinct kinds of operational behaviors have two distinct forms.
- Commands always return void (or perhaps unit, depending on the paradigm in use). That is, commands only cause a new/changed system state but never answer either the previous or new system state.
- Queries always return a current system state but never cause a change to the system state.
Note
Regarding the difference between commands and queries, it is said: "Asking a question should not change the answer."
Further, Table 1 shows the alternating command-query examples that are related. For example, requestDiscussion() is a command that causes a discussion to be created remotely in the Collaboration Context, and then a reference to it is attached to one of the AgilePM primary Aggregate types. To read the discussion information and its threaded posts, the discussionOf(id) method is used to query and answer that data.
But, there's an interesting twist.
These two related responsibilities—command operations and query operations—are not only separated from the other in the same protocol interface, they are fully segregated into two separate protocol interfaces. Assuming the protocol behaviors for products, commands would be in one product interface and queries in a completely different product interface. You could think of the segregation like this:
ProductCommands: All command operations that operate on a product aggregate types are housed on this protocol interface.ProductQueries: All queries that provide product views data are housed on this protocol interface.
That is the essence of CQRS. Rather than one protocol interface that provides both commands and queries, there are two interfaces where each provides only one kind of operation; that is, either commands or queries.
Next is the history of the company that develops the SaaS products under discussion. This company started out with the wrong assumptions about how to use DDD, and how that affected them.
The Rough Road to DDD Strategic Design
IDDD uses three Bounded Contexts as examples throughout the book. There's a fictitious company known as SaaSOvation. Obviously SaaSOvation specializes in Software as a Service (SaaS) products. The company starts out attempting to use DDD, but they lean too heavily on the tactical patterns and overlook the DDD strategic modeling tools. It was and still is a common mistake, especially to those new to the DDD approach.
Note
As I explain the background, I move quickly through it. There are considerable details missing from what is found in the full book, of course.
The road starts out very bumpy as the story begins. SaaSOvation had read about the DDD tactical modeling tools and considered the Aggregate and Repository patterns most useful. So, the team implemented their collaboration suite using those patterns. In brief, the collaboration software includes the following:
- Various collaborator roles
- Forums with threaded discussions
- Interactive and multi-use calendars
- Other team-centric tools, such as wikis
By focusing on a few tactical patterns, the developers unknowingly neglected modeling with strategic design and missed the strengths of explicit and clean boundaries between disparate concepts and those that seemed identical but that had subtle differences. This initially resulted in user authentication and access control being tightly tangled within the collaboration domain model. See Figure 4 to understand the initial problematic situation.
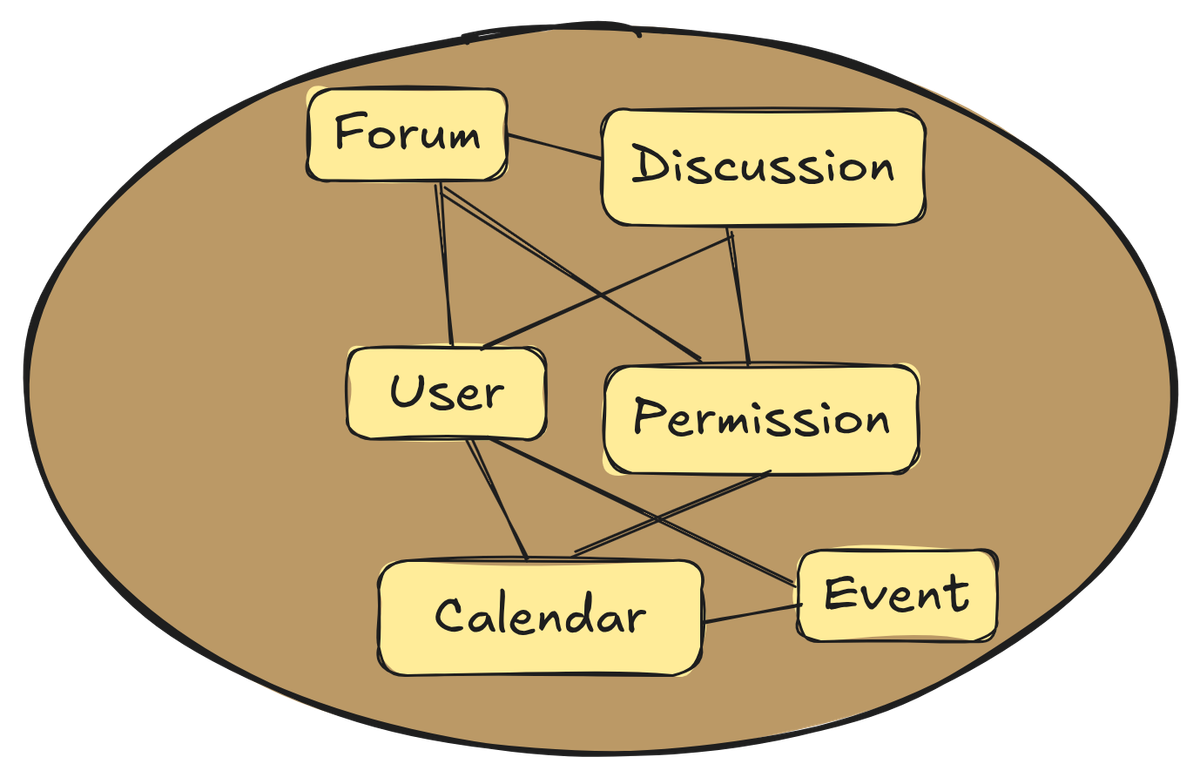
Figure 4: The collaboration product is new but with the auth tangle is already muddy and would eventually become a Big Ball of Mud.
SaaSOvation experienced problems early on as they tried to include new features and functionality, and they haven't even begun the larger AgilePM product effort. What would happen if they continued on the inter-twined monolithic endeavor without modularity? More pain and less gain.
The team eventually grasps the importance of strategic modeling and begins to course correct. This results in separating auth from collaboration by creating strict boundaries around each model, separating the two. They use Bounded Contexts to do so. The auth functionality becomes the Identity and Access Context. Further, Collaboration now has a clean boundary and is named the Collaboration Context.
Note
You may be wondering why the identity and access features are placed inside a contextual boundary. After all, auth is not a SaaSOvation Core Domain. Yet, the identity and access features and functionality use a different language that is distinct from collaboration. Being a Bounded Context doesn't mean that its domain model will receive the same tedious design attention as would a Core Domain. Even so, it is essential to support distinct and explicit Domain Events that are helpful for other Bounded Contexts that integrate. The boundary is not only justified, it is required to break the tangle and for reuse by other contexts to prevent duplicated silos. Contextual boundaries aren't established arbitrarily, as if it just "feels right."
This lays the groundwork for applying strategic design to the next product, AgilePM, which will integrate with both the Collaboration Context and the Identity and Access Context.
The AgilePM Context
Now that the teams have caught on to the critical need for DDD strategic design, the AgilePM team is ready to apply strategic modeling to their new product effort. The concepts follow Scrum. The primary concepts of the AgilePM Context are seen in Figure 5.
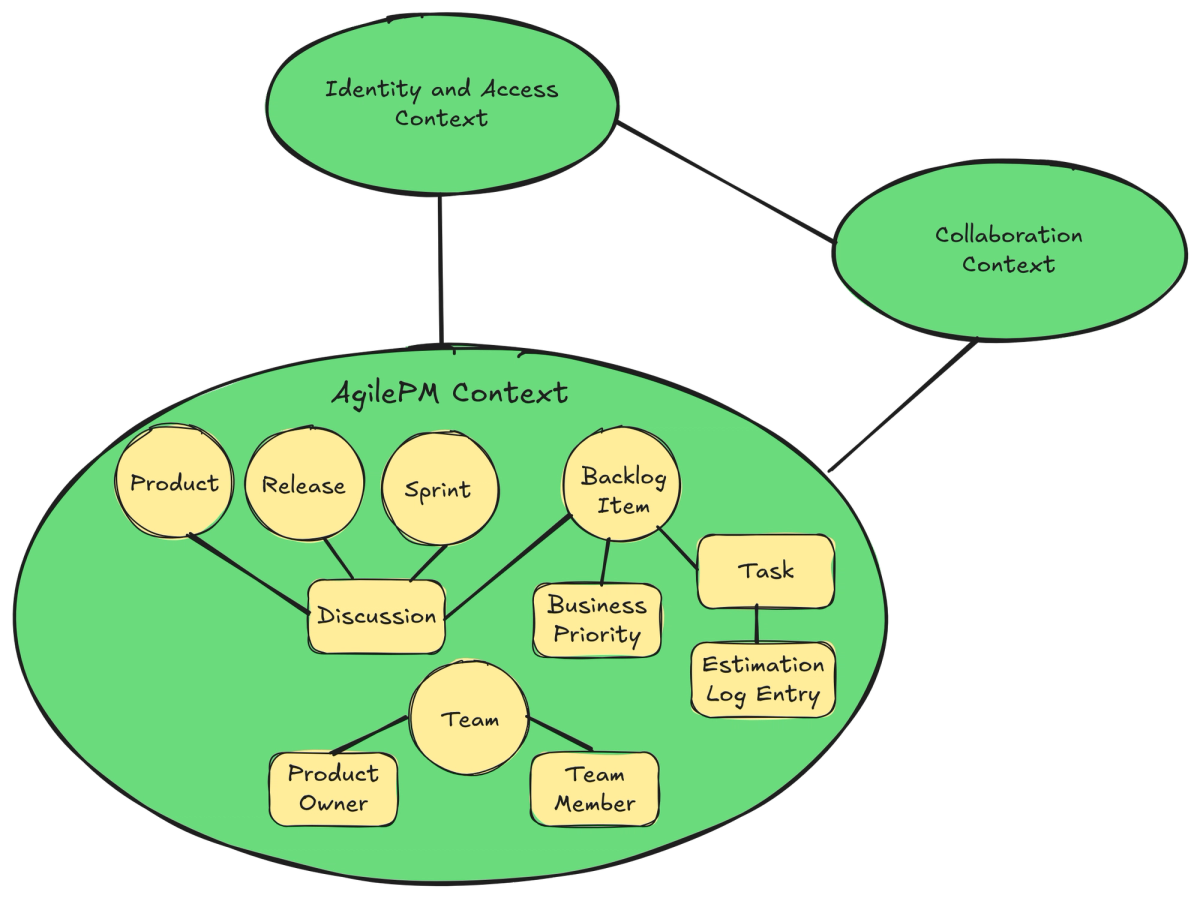
Figure 5: The AgilePM team's Context Map with primary concepts.
The Context Map in Figure 5 indicates that relationships exist between the three contexts, but it purposely omits the mapping types. Those details go well beyond the scope and main point of this article.
Note
You don't have to like/use Scrum to appreciate this example. All of my IDDD examples were conceived close to 15 years ago—as of when I wrote this article—and I chose them because most teams that I worked with and others I spoke with were by-and-large all using Scrum. The problem space complexity is high enough to justify the use of DDD, yet familiar enough for most software engineers to readily understand. The problem space also includes integration with collaboration tools and user identity and access management, a good match for demonstrating Bounded Contexts and Context Mapping. Personally, I never liked Scrum from day-2 onward. Still, as the saying goes: _Don't throw the baby out with the bathwater._ I mapped to the context of my readers while restraining my preferences. That's a practical lesson for those who want to apply DDD.
In the following, the Aggregates are implemented using EventSourcedEntity, which is a specialized Actor subclass. The concept types include:
- Product: Per Scrum, this represents the software product being built. It has any number of releases, sprints, and backlog items, as well as a team with a product owner and team members.
Productis modeled as an Aggregate. - Release: A named individual release of the product that is planned and schedule with a beginning and ending date. The maintains a number of backlog items that are scheduled to to be included with that release.
Releaseis modeled as an Aggregate. - Sprint: A named iteration that has one or more goals, holds a number of committed backlog items, as well as a start and end date. After sprint completion, a retrospective on the outcome can be recorded.
Sprintis modeled as an Aggregate. - Backlog Item: An item that represents a feature and/or some functionality to be included in the product. It has a number of tasks and an estimation for level of effort and completion.
BacklogItemis modeled as an Aggregate. - Business Priority: A calculated priority level based on qualified business needs that is given to a backlog item. All outstanding backlog items (those not done) can be used to calculate a total business priority of a given product. The
BusinessPriorityis modeled as a Value Object. - Task: A granular work item that is related to one backlog item. There are generally multiple such tasks and all must be completed for the backlog items to be done.
Taskis modeled as an Entity composed and scoped within a givenBacklogItem. - Estimation Log: For a given task, estimate the hours remaining to complete it from the current date and time. All such are maintained by the task as its estimation log. Each estimate is an entry in the log.
EstimationLogEntryis modeled as a Value Object and the log is an array (essentially a list) of those elements. - Team: Every product has a team, which is comprised of a product owner and any number of other team members.
Teamis modeled as an Aggregate.
With that background and the definition of concepts, I next present the source for a few of the Aggregate types.
AgilePM Protocols and Actors
In this article I step through the source code of two Aggregate types: Product and BacklogItem. Here's why I chose these out of the five total types.
The Product not only defines the software product being built. It is what holds the other parts of a software development effort together. That is, Product is the parent/owner of the other Aggregate concepts describe previously: Release, Sprint, BacklogItem, and Team.
It may surprise you, however, to learn that these four child concepts are not composed within the parent Product. That's due to the established rules of Aggregate design. Although I won't go in depth here, you can read about them in the three-part essay, Effective Aggregate Design. Chapter 10 of my book, Implementing Domain-Driven Design, is based on the essay. So, you'll learn a lot more about the Aggregate pattern and its intended use and find guided advice by reading the essay.
The other Aggregate type that I review is BacklogItem. This is the most complex concept to model for several reasons. Those will become clear moving forward. It's also a concept that can be improved due to careful consideration of the rules of Aggregate design.
The Product Event-Sourced Aggregate
The Product models a Scrum software product with operations. It is the parent of backlog items, releases, and sprints. The protocol is implemented as a TypeScript interface.
export interface Product extends ActorProtocol {
initiate(...): Promise<void>
changeDescription(...): Promise<void>
changeProductOwner(...): Promise<void>
requestDiscussion(): Promise<void>
attachDiscussion(...): Promise<void>
timeOutDiscussionRequest(...): Promise<void>
planSprint(...): Promise<void>
scheduleRelease(...): Promise<void>
}This is a command-only interface following CQRS. Queries are performed via the read model maintained by projections. Those are covered in a subsequent article.
See the source code on GitHub [6] for complete protocol documentation (JSDoc). The command operations are self explanatory. Only the parameters are missing from the above code snippets.
There are a few factory methods used to constitute and reconstitute Product instances.
export namespace Product {
streamNameFor(
tenant: Tenant,
productId: ProductId)
: string {
...
}
initiate(
tenant: Tenant,
productId: ProductId,
name: string,
description: string,
productOwnerId: ProductOwnerId)
: Promise<Product> {
...
}
of(
tenant: Tenant,
productId: ProductId)
: Product {
...
}
}First consider the initiate() factory method, which answers a completely new Product aggregate instance as a Promise:
const product = await Product.initiate(tenant, productId, name, description, productOwnerId)These factory methods are implemented using an explicit namespace declaration. Programmers resolve the namespace using an expression in which the methods are declared so that the method can be referenced. This gives developers the means to use an approach that looks like static/class methods available in other languages, such as Java and C#. This may be considered closer to expressing the ubiquitous language. Yet, a free-standing function could express it even more clearly:
export const initiateProduct = Product.initiate
...
const product = await initiateProduct(tenant, productId, name, description, productOwnerId)One nice thing about TypeScript is that you can use the style that's more natural to the team, which includes domain experts. The key is accomplishing expressive fluency.
Of course, in Java and C# this approach can also be used by means of static import and static using, respectively. Choices, choices. Having options is a good thing, as long as they are good options.
Per the improved ubiquitous language, a product is initiated rather than simply created. "Initiate" is not just a fancy way of saying "create"; it's actually the way the team spoke all along of bringing a product into existence. It just took some time for the feedback loop within the team of domain experts and developers to realize that their preferred term "initiate" be entered into the AgilePM ubiquitous language to replace "create."
Note
Software developers habitually use CRUD and collection terminology. It's easy to do so because our programming facilities—APIs and libraries—are chock-full of them. Our brains become wired to those and we start to think that every abstraction is just a variable, container, or disk/database.
Pro Tip: Challenge yourself and your team to reject CRUD and collection terminology and seek out more fitting words and expressions directly from the business.
The method Product.streamNameFor() answers the string name (id) of the Product event stream belonging to the tenant that has the given Product identified by the unique productId. It's used for when the stream's name must be used to fully identify the individual stream:
const streamName = Product.streamNameFor(tenant, productId)The stream name has the following format:
Product-${tenant.id}-${productId.id}The second and third segments are easily identified as the unique tenant identity and the unique product identity, both of which use UUID v4 underneath.
The first segment, "Product-", is obviously identifying the type of stream, but it may not be obvious why it's used. Using "P-" rather than the former would work, but the former is more descriptive and explicit. It also leaves room for other types that begin with "P-" that could be introduced in the future.
The point of using a type-prefix segment is to provide a means to automatically project a category-stream; that is, any event that has type "Product-" can be queried from the stream that results from its special, automated projection. It's just one of the many benefits of using KurrentDB.
This id is used internally by Product.of() to reconstitute the preexisting Product instance from its event stream:
const product = Product.of(tenant, productId)Notice, no repositories! This is where the DomoActors and DomoTactical libraries shine, which I demonstrate below.
Returning to the Product aggregate, the protocol interface is implemented by ProductActor that also extends EventSourcedEntity, which provides the event sourcing interface.
class ProductActor extends EventSourcedEntity implements Product {
private _tenant!: Tenant
private _productId!: ProductId
private _name!: string
private _description!: string
private _productOwnerId!: ProductOwnerId
private _discussionId?: string
private _discussionRequested: boolean = false
...The ProductActor is a technical implementation artifact. Clients only see and use the Product protocol.
The technical component is an Actor that implements the Product protocol while adding special behavior. It is specialized to handle Event Sourcing—both persisting events to its event stream and reconstituting its state from its event stream. Both writing and reading state are managed by KurrentDB. The specific actor behavior that integrates with KurrentDB is abstracted away from the application developers. How so?
Take a look at a portion of the implementation of Product.initiate(), both the factory method in the namespace and the message handler in ProductActor.
class ProductActor extends EventSourcedEntity implements Product {
...
constructor(tenant: Tenant, productId: ProductId) {
super(Product.streamNameFor(tenant, productId))
this._tenant = tenant
this._productId = productId
}
async initiate(
name: string,
description: string,
productOwnerId: ProductOwnerId
): Promise<void> {
if (this._name) {
return
}
if (!name?.trim()) {
throw new Error('Product name cannot be empty')
}
if (!description?.trim()) {
throw new Error('Product description cannot be empty')
}
await this.apply(ProductInitiated.with(
this._tenant,
this._productId,
name.trim(),
description.trim(),
productOwnerId
))
}
...
}The constructor accepts the Tenant and ProductId parameters, and from those initializes the super class state with the stream name to be used by KurrentDB for this particular Product instance.
Studying the above initiate() message handler, the guards protect against re-initiating the product after the first-time initiation and also prevents use of invalid name and description parameters. The key to KurrentDB event persistence is using apply(source: DomainEvent). As seen in the above example, the new event to be applied is ProductInitiated with the valid initiate() parameters.
Internally, the EventSourcedEntity method apply() sends a message to the JournalAdapter actor, which in turn appends the event to the new event stream in KurrentDB. The following is the actor messaging chain from the Product all the way to the KurrentDBClient:
- Product: initiate()
- EventSourcedEntity: apply(source: ProductInitiated)
- JournalAdapter: append(streamName, streamVersion, source, metadata)
- KurrentDBActor: appendToStream(streamName, events, options)
- KurrentDBClient: appendToStream(streamName, eventData, appendOptions)Ultimately, the EventSourcedEntity method apply() message results in the appendToStream() message being delivered to the KurrentDBActor, which in turn uses the KurrentDBClient. The KurrentDBClient is distributed by the Kurrent team. It's used to persist the event(s) and any metadata that may be associated with the event(s) as a remote request payload to the KurrentDB instance.
By the way, the metadata parameter is optional and may be passed by the concrete Aggregate type, such as Product, to apply(). If used, metadata might include some causal data such as username and role, and if applicable, even the previous event-command pair that eventually caused this event to occur.
One important detail is missing. How is a new event, such as ProductInitiated, applied to the state of the Product instance? The following code demonstrates:
class ProductActor extends EventSourcedEntity implements Product {
...
static {
EventSourcedEntity.registerConsumer(
ProductActor, ProductInitiated,
(product, event) => product.whenProductInitiated(event)
)
...
}
...The class static initialization block is used to register a callback for each event type with the EventSourcedEntity (actually its base SourcedEntity class) for each event type. The registered method is called after the event is persisted:
...
private whenProductInitiated(event: ProductInitiated): void {
this._tenant = Tenant.of(event.tenantId)
this._productId = ProductId.of(event.productId)
this._name = event.name
this._description = event.description
this._productOwnerId = ProductOwnerId.from(event.productOwnerId)
}
...
}This guarantees that only valid, persisted events are reflected in the current state.
I am in the habit of using when as the name prefix for such methods, but that's not required. You could use onProductInitiated() or just about any name that makes sense.
To step through what occurs when one or more new events are applied, consider the following:
- The
Productcallsapply(event)orapply(events) - The
snapshot()callback is called (see below) - A snapshot, if any, and one or more events are persisted in KurrentDB
- The callback method registered to apply the given event type to the state is called
- All applicable event state is used to mutate the Aggregate state
These callback methods are used, not only when a new event is first applied and persisted. They are also used when the Aggregate instance is being reconstituted from its KurrentDB-persisted event stream. State reconstitution is handled automatically by the EventSourcedEntity, as noted above. Just use the Product.of() factory method:
export namespace Product {
...
export function of(
tenant: Tenant,
productId: ProductId
): Product {
return stage().actorFor<Product>(
productProtocol,
undefined,
'default',
undefined,
tenant,
productId
)
}
}After the Product (or other Aggregate type) is instantiated by Stage.actorFor(), the EventSourcedEntity automatically restores the preexisting event stream internally, if it exists. This is accomplished when the built-in Actor Model life-cycle message, start(), is received. All Actor types may choose to handle the start() message:
export abstract class SourcedEntity<T> extends EntityActor {
...
override async start(): Promise<void> {
await this.restore()
}
...
}Internally, restore() can recover states that are based on an event stream only or both a snapshot (intermediate state) and the trailing segment of the event stream since the snapshot was taken.
For example, assume that both an event stream and snapshots are used for Product persistence. To elaborate on the above step 2, consider these details:
2. The snapshot() callback is called (see below)
- If overridden and a version threshold is reached to take a state snapshot, a new state instance is returned
- Otherwise
nullis returned by the base or the override
Here's source code for a snapshot state type and a snapshot() implementation:
interface ProductState {
tenantId: string
productId: string
name: string
description: string
productOwnerId: string
discussionId?: string
discussionRequested: boolean
}
class ProductActor extends EventSourcedEntity implements Product {
...
protected snapshot<ProductState>(): ProductState | null {
// Only snapshot after the aggregate has been initiated
if (!this._name) return null
// And for every 100th version
if (this.nextVersion() % 100 !== 0) return null
return {
tenantId: this._tenant.id,
productId: this._productId.id,
name: this._name,
description: this._description,
productOwnerId: this._productOwnerId.toString(),
discussionId: this._discussionId,
discussionRequested: this._discussionRequested,
}
}
...The ProductState holds the snapshot state to be persisted with the event stream.
Now consider state reconstitution from persistence. Again assume both an event stream and snapshots exist in KurrentDB for a given Product instance. To bring back the Product state:
- The snapshot of intermediate state is read
- The partial stream of events following the snapshot's version is read
- The
ProductStatesnapshot is set as the initialProductinstance state - All events in the partial stream are applied one-by-one through the state-mutating callbacks; that is, in this case the appropriate
when...()methods
The state is now fully reconstituted from KurrentDB persistence. Here's the additional snapshot-restoring callback:
class ProductActor extends EventSourcedEntity implements Product {
...
protected async restoreSnapshot(
snapshot: ProductState,
currentVersion: number
): Promise<void> {
this._tenant = Tenant.of(snapshot.tenantId)
this._productId = ProductId.of(snapshot.productId)
this._name = snapshot.name
this._description = snapshot.description
this._productOwnerId = ProductOwnerId.from(snapshot.productOwnerId)
this._discussionId = snapshot.discussionId
this._discussionRequested = snapshot.discussionRequested
}
...
}Rather than walking through all Product command message handlers, suffice it to say that all of the behaviors work in the same manner as initiate(). Again, view the full source code on my GitHub account.[6]
With the Product implementation in mind, I next introduce the BacklogItem.
The BacklogItem Event-Sourced Aggregate
As is true with the patterns used by the Product implementation, the BacklogItem does the same:
- When a command is requested of the
BacklogItem- Guards are used to ensure parameters are basically legal and valid
- Any additional business logic is run and derived values are determined
- One or more new events are applied to the
BacklogItem - Persistence is handled asynchronously by the Actor Model based actor type—
BacklogItem-->EventSourcedEntity-->SourcedEntity - The registered
when...()(or differently named) callback method is called by the base to mutate the state of theBacklogItem
In summary, these are the primary types in BacklogItem.ts:
export interface BacklogItem extends ActorProtocol {
plan(...): Promise<void>
commitTo(...): Promise<void>
uncommit(): Promise<void>
scheduleTo(...): Promise<void>
unschedule(): Promise<void>
assignStoryPoints(...): Promise<void>
changeType(...): Promise<void>
defineTask(...): Promise<void>
describeTask(...): Promise<void>
estimateTaskHours(...): Promise<void>
changeTaskStatus(...): Promise<void>
assignTaskVolunteer(...): Promise<void>
summarize(...): Promise<void>
tellStory(): Promise<void>
markAsRemoved(): Promise<void>
requestDiscussion(): Promise<void>
attachDiscussion(): Promise<void>
assignBusinessPriority(...): Promise<void>
renameTask(...): Promise<void>
removeTask(...): Promise<void>
}
export namespace BacklogItem {
streamNameFor(
tenant: Tenant,
backlogItemId: BacklogItemId)
: string {
...
}
plan(
tenant: Tenant,
productId: ProductId,
backlogItemId: BacklogItemId,
summary: string,
story: string,
type: BacklogItemType
)
: Promise<BacklogItem> {
...
}
of(
tenant: Tenant,
productId: ProductId,
backlogItemId: BacklogItemId
): BacklogItem {
...
}
class BacklogItemActor extends EventSourcedEntity implements BacklogItem {
private _tenant!: Tenant;
private _productId!: ProductId;
private _backlogItemId!: BacklogItemId;
private _summary!: string;
private _story!: string;
private _type!: BacklogItemType;
private _status!: BacklogItemStatus;
private _storyPoints?: StoryPoints;
private _sprintId?: SprintId;
private _releaseId?: ReleaseId;
private _tasks: Map<string, Task> = new Map();
private _discussionRequested: boolean = false;
private _discussionId?: string;
private _businessPriority?: BusinessPriority;
private _removed: boolean = false;
...
async plan(
summary: string,
story: string,
type: BacklogItemType
): Promise<void> {
if (this._summary) {
return;
}
if (!summary?.trim()) {
throw new Error('Summary cannot be empty');
}
if (summary.trim().length > 100) {
throw new Error('Summary must be 100 characters or less');
}
if (story && story.trim().length > 65000) {
throw new Error('Story must be 65000 characters or less');
}
await this.apply(BacklogItemPlanned.with(
this._tenant,
this._productId,
this._backlogItemId,
summary.trim(),
story?.trim() ?? '',
type
));
}
...
}Given that the plan(...) message the first command to be requested for a new BacklogItem (see: BacklogItem.plan() factory in the namespace BacklogItem), BacklogItemPlanned is the initial event to be persisted into its event stream.
The BacklogItem has 21 different event types that are used to represent an instance state:
BacklogItemPlanned, BacklogItemCommitted, BacklogItemUncommitted, BacklogItemScheduled, BacklogItemUnscheduled, BacklogItemStoryPointsAssigned, BacklogItemTypeChanged, BacklogItemSummarized, BacklogItemStoryTold, BacklogItemMarkedAsRemoved, BacklogItemStatusChanged, BacklogItemDiscussionRequested, BacklogItemDiscussionAttached, BacklogItemBusinessPriorityAssigned, TaskDefined, TaskDescribed, TaskHoursEstimated, TaskStatusChanged, TaskVolunteerAssigned, TaskRenamed, TaskRemoved
Isn't that excessive? Yep. You have to wonder, "Is there a better way?" Yep. The shear number of command messages, message handlers, and event types give off a very distinct smell. You might instead argue: If the BacklogItem needs this number of commands and related events, it's hard to fault the design.
Whatever you might opine, there are a few other factors to consider:
- How are CQRS projected views and queries to be provided?
- The second law of thumb of Aggregate design is: Design small Aggregates
- In Implementing Domain-Driven Design I reasoned on why the
BacklogItemwasn't too large from a memory footprint and cognitive load (complexity) perspective - Yet, does that viewpoint consider the spirit of the other three laws of thumb?
- For example, the first is: Protected true business invariants inside aggregate boundaries. Okay, invariants are protected. But does the design buckle under certain use cases? What if the current boundary isn't the best?
- What is involved in refactoring a larger event-sourced aggregate to make it smaller?
- In Implementing Domain-Driven Design I reasoned on why the
- And what about the fourth rule? Update other aggregate instances using eventual consistency
- I haven't yet discussed committing a
BacklogItemto aSprint:backlogItem.commitTo(sprint). Is that the end of the use case? Not according to the team that's building the AgilePM Context in Implementing Domain-Driven Design.
- I haven't yet discussed committing a
Those are all valid points of concern. I don't offer potential solutions just yet. I want to bring those up in my upcoming installments. And to say the least, beyond event stream persistence, addressing these three concerns is where KurrentDB proves to be a game changer in Event-Driven Architectures.
Going Enterprise
The core of KurrentDB is in open source. As someone who has built a large, open source platform with 25 major components (e.g. actors, clustering, compute grid, persistence, HTTP and GraphQL servers, and much more) and having paid developers to work with me on it, I can tell you from experience that without earning revenue in return, remaining generous becomes tedious.
Naturally then, Kurrent offers a paid-for Enterprise edition that takes serious users well beyond the general features of Event Sourcing. If that describes your company and teams, here are some of the components offered with Enterprise:
1. Kubernetes Operator: This provides several benefits, including:
- Managed database clustering with operational automation
- Simplified cluster deployment
- Built-in security management by means of Kubernetes Secrets
- Automatic archiving into offline nodes for cost-effective storage
- Advanced node placement by type via the Kubernetes scheduler
2. Auto-Scavenging: Ummm, wait a moment. In an append-only database, what is there to scavenge?
- Yes, you can mark facts as deleted
- One good reason is for stream migrations, which I promised to cover that in my next installment
- Another is compliance with law, such as with personal private information under GDPR
- When facts are marked for deletion, scavenging compacts storage chunks and retains a clean $all stream
- Scavenging and compaction is a very sophisticated process, even combining adjacent compacted chunks that together fit into one chunk
3. Connectors: Pre-built, in-database integration components that either feed sinks or consume sources
- A sink is an external mechanism that receives KurrentDB stream data
- Supported sinks: HTTP, Kafka, Elasticsearch, MongoDB, RabbitMQ, Pulsar, SQL, and Serilog
- A source is an external mechanism that provides stream data to KurrentDB
- Supported sources: Kafka
Note
If you use Kurrent Cloud, there's more included. Auto-scavenge, connector, and other enterprise features are there in a fully-managed environment.
**Meaning: It's not your up-time.**
Provision a database instance and go.
These save significant time and effort, and raise the quality of your KurrentDB infrastructure.
As I already indicated, my follow-up articles will lead to how Auto-Scavenging and Connectors can benefit you and your team.
References
[1] See Implementing Domain-Driven Design
[2] There were earlier concepts that helped influence serverless, such as with Google App Engine in 2008, but let's stick with late 2014 as the true introduction. See AWS Lambda First Release
[3] See Serverless as a Game Changer by Joe Emison, one of the books in my signature series.
[4] Implementing Domain-Driven Design: Java Examples and Implementing Domain-Driven Design: C# .NET Examples
[5] DomoActors-TS , DomoTactical-TS , DomoTacticalStorage-TS
[6] Implementing Domain-Driven Design: Domo+TypeScript+KurrentDB Examples
